
导读
非线性运算是几乎所有现代信息处理任务(如机器学习、模式识别和通用计算)的核心。然而,长期以来,光学系统在实现此类运算时始终面临挑战:大多数非线性光学效应往往较弱、能耗高且响应速度有限。
近日,加州大学洛杉矶分校电气与计算机工程系的Ozcan教授团队提出一种光学计算框架,通过结合衍射处理与波前编码,使其能够在极高的速度和空间密度下,实现大规模并行的非线性函数运算。该方案确立了衍射光学处理器作为一种可扩展的平台,能够实现大规模并行的通用非线性函数逼近,为基于线性材料的模拟光学计算开辟了新的可能。
相关研究成果以 “Massively parallel and universal approximation of nonlinear functions using diffractive processors” 为题发表于eLight(影响因子32.1,入选两期卓越计划)。
面对摩尔定律趋近极限与人工智能计算需求的激增,探索新型高效计算范式已迫在眉睫。在此背景下,衍射光学处理器应运而生。此类处理器利用深度学习优化的多层源衍射结构,在光的传播过程中对波前进行精确调制,从而实现高速、低功耗的类神经形态计算。然而,光学计算长期面临一个核心瓶颈:如何高效实现非线性运算。传统方案依赖非线性光学效应,但这些效应通常很弱,且伴随着高能耗或慢响应的问题。而基于光电转换或特定非线性材料的方案,也常受限于高损耗、响应慢或对极端光强的依赖。近期,虽有研究尝试使用线性光学手段(例如基于空间光调制器(SLM)的多平面注入或光腔反馈)来模拟非线性,但这些方法往往未能完全摆脱对数字处理的依赖,或导致系统结构过于复杂。因此,如何在纯线性、无源的光学框架下实现可扩展的非线性计算,已成为当前光学信息处理领域的关键挑战。
本文提出了一种全新的基于光学计算框架的非线性计算策略:通过将非线性函数的输入变量结构性地编码到光波前的相位中,并利用完全由线性材料构成、经过优化设计的静态衍射光学结构进行处理,从而实现了线性光学系统对非线性函数的通用逼近(图1)。在这一架构中,每一个衍射极限分辨率下的输出像素都代表一个独立的非线性函数,从而在紧凑、无源的光学系统中实现了极高的并行计算能力。UCLA 研究人员在理论与实验上均证明,这些衍射处理器是通用的非线性函数逼近器,可实现任意带限非线性函数的映射,包括多变量和复值函数,并可通过全光学级联方式进一步构建更复杂的运算体系。研究中,团队成功逼近了多种数字神经网络中常见的非线性激活函数,如sigmoid、tanh、ReLU(线性整流单元)以及softplus 等。
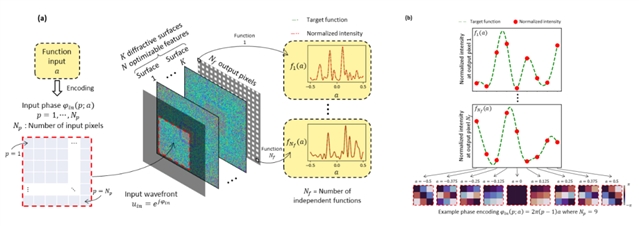
图1:大规模并行的衍射光学非线性函数计算:(a) 输入函数被编码至光波前的相位中,经衍射光学处理器传播后,各输出像素处的光强对应相应函数的输出值。(b) 输出非线性函数的拟合结果
在数值仿真中,研究团队展示了该光学架构在极高并行度下的强大计算能力。研究团队设计并训练了五组衍射光学处理器,分别对应不同的非线性函数数量Nf 。图2展示了各设计的函数逼近误差分布:随着目标函数数量的增加,误差的分布范围与上限略有上升,反映出任务复杂度的提升;然而,即便在 一百万个非线性函数的极端情况下,误差仍保持在极低水平,充分体现了该架构在大规模并行非线性函数计算中的可扩展性与鲁棒性。
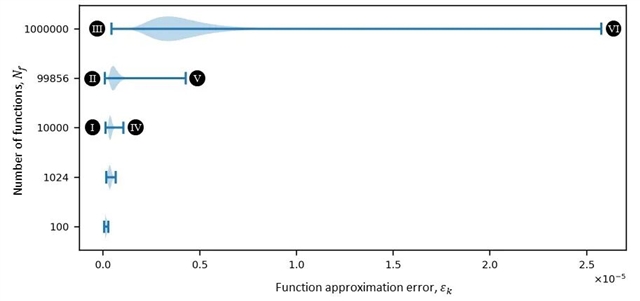
图2:衍射光学处理器在不同目标非线性函数数量Nf(100-1,000,000)的误差分布
研究团队还进行了实验验证,证明了该系统同时学习并执行多种非线性函数的能力。在实验中,团队对35个不同的非线性函数进行了学习,当系统收敛后,输出光强能够准确地再现目标函数的非线性关系(图3)。这一结果验证了衍射光学处理器在真实物理系统中可实现多函数并行非线性计算的可行性。
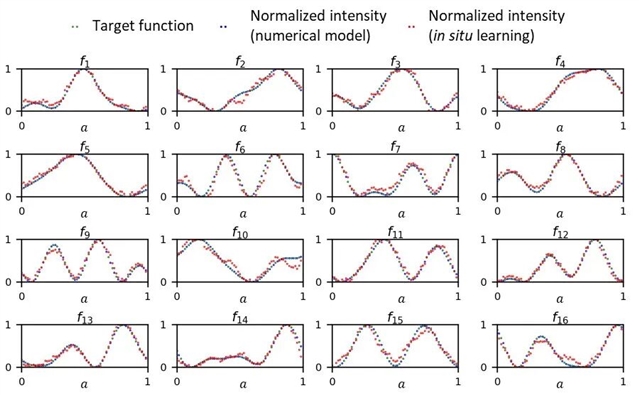
图3:实验测得的部分非线性函数输出结果
总结与展望
本研究提出了一种衍射光学计算框架,该框架仅使用线性衍射材料便能实现通用非线性函数逼近。通过将基于相位的波前编码与优化的衍射变换相结合,该方法能够在极高的速度和空间密度下,实现大规模并行的非线性函数运算,可扩展至处理从数百到数百万个独特的非线性函数。随着高端图像传感器(数亿像素级)的发展,该系统有潜力并行计算上亿个非线性函数,全部以光速完成、无需非线性光学材料或电子后处理。这一能力有望推动超高速模拟计算、光神经形态计算及高通量光学信号处理等领域的发展。(来源:中国光学微信公众号)
相关论文信息:https://doi.org/10.1186/s43593-025-00113-w
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






