近日,中国科学院沈阳自动化研究所机器人学研究室研究员丛杨团队提出了一种终身度量学习算法,相关成果发表于IEEE Transactions on Cybernetics。
在线度量/相似性学习具有有效处理大规模数据的优势,已经在数据挖掘、信息检索和计算机视觉等领域获得成功的实际应用。不同于大量存在的离线学习度量模型的批量学习方法,在线学习能利用一个或者一组样本迭代的更新度量模型,同时能更适合序列数据的任务。然而,目前大部分的在线度量学习模型只能在固定度量任务的基础上实现在线学习,不能增加新的任务。
沈阳自动化所研究团队利用终身学习来模拟“人类学习”,即将当前的度量扩展到新的任务同时保持当前度量任务不变。例如,在2D图像识别系统中,一个度量学习系统能很好地识别一个图片中是否包含已知类别的目标,但用户经常期望这一能力可以扩展到新的任务,即检测一个新的类别目标。
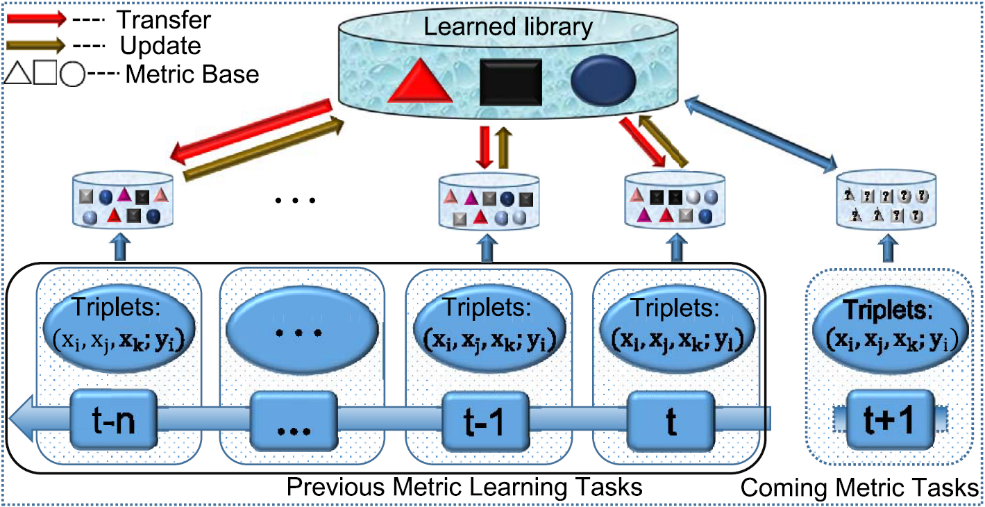
终身度量学习(LML),意图从旧的任务中学习共享的度量参数同时保持以前任务的表现。在所有任务都位于一个低维共享子空间的假设上,LML学得一个称谓“终身字典”的知识库作为所有度量模型的共享基,同时所有学得的模型都可以作为终身字典的稀疏组合。具体而言,终身字典首先从第一个训练任务通过聚类的形式初始化,当新的第t+1个任务到达系统时,LML通过迁移终身字典中的基知识来学习新的度量模型,同时利用当前和以前的任务来更新终身字典。
实验结果表明,该模型能够很好应对度量任务不断增加的场景,并取得了和多任务度量学习相似的结果。
该项研究获得国家自然科学基金和机器人学国家重点实验室的支持。(来源:中国科学院沈阳自动化研究所)
终身度量学习模型
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。