|
|
|
|
|
税务风险检测新进展:数据挖掘技术的应用与展望 Engineering |
|
|
论文标题:A Survey of Tax Risk Detection Using Data Mining Techniques
期刊:Engineering
DOI:https://doi.org/10.1016/j.eng.2023.07.014
微信链接:点击此处阅读微信文章

西安交通大学师斌科研团队在中国工程院院刊《Engineering》发表题为 “A Survey of Tax Risk Detection Using Data Mining Techniques” 的综述论文。该文章对全球现有的基于数据挖掘技术的税务风险检测方法进行了全面概述和总结,为该领域的研究和实践提供了重要参考。
税收是国家重要的收入来源,但税务风险行为,如逃税、欺诈等,严重损害国家利益,扰乱市场经济秩序。精准的税务风险检测至关重要,然而传统检测方法,像人工选案、基于规则选案等,因高度依赖人力和专家知识,在面对复杂海量的税务数据时存在很大局限性。
随着信息技术的发展,基于人工智能和数据挖掘的税务风险检测方法应运而生。论文指出,这类方法可分为非基于关系和基于关系的两类,共计 14 种。非基于关系的方法主要利用纳税人的上下文属性识别风险,例如关联规则,能发现数据中属性的相关性,但随着数据量增加计算复杂度会显著上升;基于树的模型可处理高维样本,结果易于理解,却容易过拟合。此外,支持向量机(SVM)、贝叶斯分类器、逻辑回归(LR)、聚类模型、人工神经网络和混合模型等也各有优劣。比如 SVM 在小规模数据分类上效果好,但处理大规模数据时计算复杂且对缺失数据敏感;人工神经网络准确率高,但训练样本需求大、可解释性差。
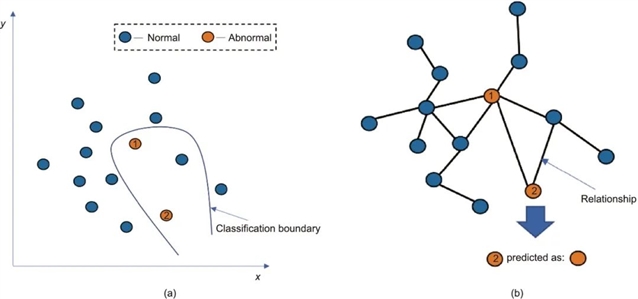
图1. 非基于关系的税务风险检测和基于关系的税务风险检测的差异。(a) 非基于关系的税务风险检测;(b)基于关系的税务风险检测。
基于关系的方法则充分利用税务场景中实体间的交互信息。图模式匹配通过挖掘税务交易网络查找逃税群体,结果易理解,但数据规模大时计算量大,且依赖手动定义模式;图表示学习能利用结构和关系信息提升检测性能,不过图规模增加时会出现可解释性差和计算复杂度高的问题;视觉分析通过可视化表示帮助理解分析,但呈现的数据可能存在主观性和偏见。
尽管现有方法取得了一定进展,但仍面临诸多挑战。如知识碎片化导致难以整合和利用财政税收知识;检测结果不可解释,难以提供直接证据;风险检测算法成本高;算法依赖标记信息,而税务场景中标记数据获取困难。
展望未来,知识导向和数据驱动的大数据知识工程将是税务风险检测领域的发展趋势。论文提出了四个未来研究方向:一是进行基于大数据知识工程的碎片化知识融合,将多源异构数据转换为结构化知识库;二是开展基于大数据知识工程的可解释性认知推理,生成可解释的证据链;三是设计大规模税务情景下的高效风险检测方法;四是探索低资源情景下的风险检测方法,如利用主动学习、无监督学习等技术。
这篇论文为税务风险检测领域的研究和实践指明了方向,有助于推动税务风险检测从信息化向智能化转型,提升国家税收治理能力。
文章信息:
A Survey of Tax Risk Detection Using Data Mining Techniques
基于数据挖掘技术的税务风险检测方法评述
作者:
郑庆华, 徐一明, 刘慧祥, 师斌*, 王嘉祥, 董博
引用:
Qinghua Zheng, Yiming Xu, Huixiang Liu, Bin Shi, Jiaxiang Wang, Bo Dong. A Survey of Tax Risk Detection Using Data Mining Techniques. Engineering, 2024, 34(3): 43–59
开放获取论文:
https://doi.org/10.1016/j.eng.2023.07.014
更多内容
人工智能的发展:实现数据集、AI模型、建模软件和硬件体系逻辑结构的一致性?
地理大数据揭示中国城市建成环境存量空间模式
李静海院士团队:未来数据系统的逻辑与架构
海运数据驱动建模:应对不确定性,优化全球物流
Engineering征稿启事:人工智能赋能工程科技
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






