近日,中山大学智能工程学院教授梁小丹团队与深圳引望智能技术有限公司,联合上海交通大学、上海创智学院,发布了全新主动几何集成框架GeoThinker。相关研究成果发表于arXiv预印本平台。
 GeoThinker模型框架。研究团队供图
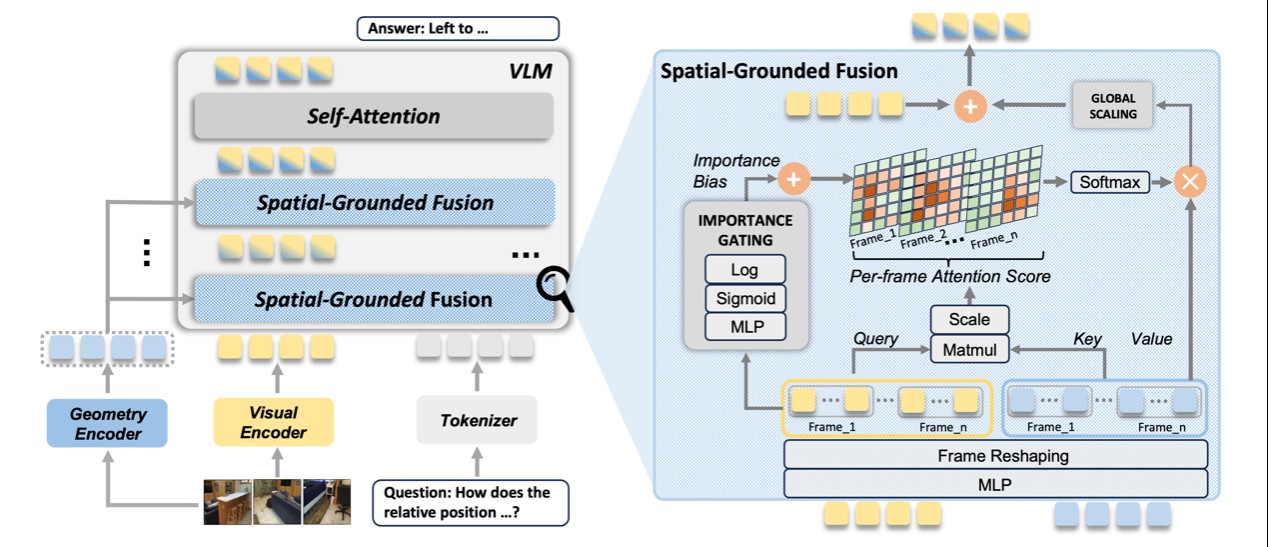
GeoThinker模型框架。研究团队供图
目前的视觉语言模型在物体识别上已经非常成熟,但在理解复杂的3D物理空间关系时仍面临挑战。核心瓶颈在于传统的“被动融合”模式,即模型无差别地接收所有几何信息,导致视觉语义与底层几何位置难以精准对齐。这种方式不仅引入了大量如地板、墙面等无关的背景噪声,掩盖了关键的空间逻辑,还使得模型在处理复杂推理任务时精度不足,难以真正“读懂”三维物理世界。
针对这些痛点,梁小丹团队与合作者提出了名为GeoThinker的全新主动几何集成框架。GeoThinker实现了从“被动融合”向“主动感知”的范式转变,其核心在于构建了“按需查询”的智能机制。通过空间基座融合和重要性门控(IG)等核心架构,模型能够根据具体任务上下文,主动识别并定向提取关键的空间纹理信息。这种设计就像为模型装上了“智能滤镜”,使其能自发关注物体边界和关键结构,同时屏蔽冗余的背景干扰。
实验结果显示,GeoThinker在多项权威空间智能基准测试中展现了极强的领先性。它在VSI-Bench上以72.6分的成绩刷新了SOTA纪录,性能显著优于GPT-5和Gemini-3-Pro等闭源大模型。在全球EASI综合榜单中,GeoThinker位列总榜第6,是开源界公认的标杆模型。
此外,该框架在具身智能机器人指代和自动驾驶规划决策等实际应用中也表现卓越,即便在极低分辨率的模糊图像下依然能保持稳健的空间推理能力。这一研究证明,空间智能的未来在于模型能够根据需求主动、精准地整合几何结构信息。
相关论文信息:https://doi.org/10.48550/arXiv.2602.06037
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。






