近日,由中国计算机学会(CCF)主办的第21届全国高性能计算学术大会(CCF HPC China 2025)在内蒙古鄂尔多斯召开。大会上,中国工程院院士、中国计算机学会理事长孙凝晖第一个作特邀主旨报告。在题为“AI赋能科学发现”报告中,他分享了自己对这一备受关注话题的思考。
 孙凝晖在CCF HPC China 2025大会上。组委会供图
孙凝晖在CCF HPC China 2025大会上。组委会供图
“第五范式”登上历史舞台
他首先谈到,“科学智能”(AI for Science,也即“AI赋能科学发现”)这一研究范式的涌现,始于AlphaFold在蛋白质结构预测上的突破。2020年,AlphaFold在CASP14大赛中成功预测了2/3的目标蛋白结构,开启了基于人工智能预测蛋白及核酸等分子结构的历史进程。
“(借助高性能计算机)从头计算预测蛋白质结构的(传统)方法,经过二三十年未能取得显著进展;后来,AlphaFold推进了一大步。”孙凝晖说,AlphaFold的出现,标志着AI成为科学发现的基本手段之一。
接着,2024年诺贝尔物理学奖和化学奖接连授予了人工智能基础理论和科学发现领域的科学家,展现了对人工智能的“偏爱”。孙凝晖认为,这标志着国际学术界公认了人工智能技术已进入科学领域,“代表着科研范式的重大改变”。
“融合大模型、大算力、大数据和大团队服务等特点的科学研究,(对科学发现的作用)就像大科学装置一样,是一个新的范式。”孙凝晖说,新研究范式的形成,除了“大模型、大算力、大数据”之外,还离不开“包括物理、化学、生物、人工智能等各领域科学家和工程师组成的团队长期的工作”以及企业资金的长期支持,诸般要素齐聚“才让这件事发生”。
孙凝晖表示,在“AI赋能科学发现”之前,现代科学活动中存在四种范式,即基于实验观察的科学实验范式、依赖科学家的理论推演范式、借助计算设备的科学计算或数值模拟范式、基于实验和理论数据计算的科学数据范式。如今,AI赋能科学发现当属“第五范式”,正在登上历史舞台。
帮助科学家从“增肌强体”到“赋予大脑”
AI到底如何赋能科学发现?
孙凝晖提出,从信息化视角来看,AI赋能科学发现的核心在于将构建包括观测(Observe)、模拟(Orient)、猜想(Hypothesis)与实验(Verify)四个环节,并将数据驱动和智能算法驱动引入到这四个环节中,形成一个“OOHV全环的AI赋能”。
“在这四个环节中,信息技术总能发挥作用,它们让知识的获取、分享和检索、交换更加方便,让信息的抽取更简单。”孙凝晖展开谈到,推演模拟环节本质上是“高性能计算+AI”,而机器学习、大模型能通过处理科学数据发现规律、验证猜想,观察和实验未来也可倚靠具身智能。
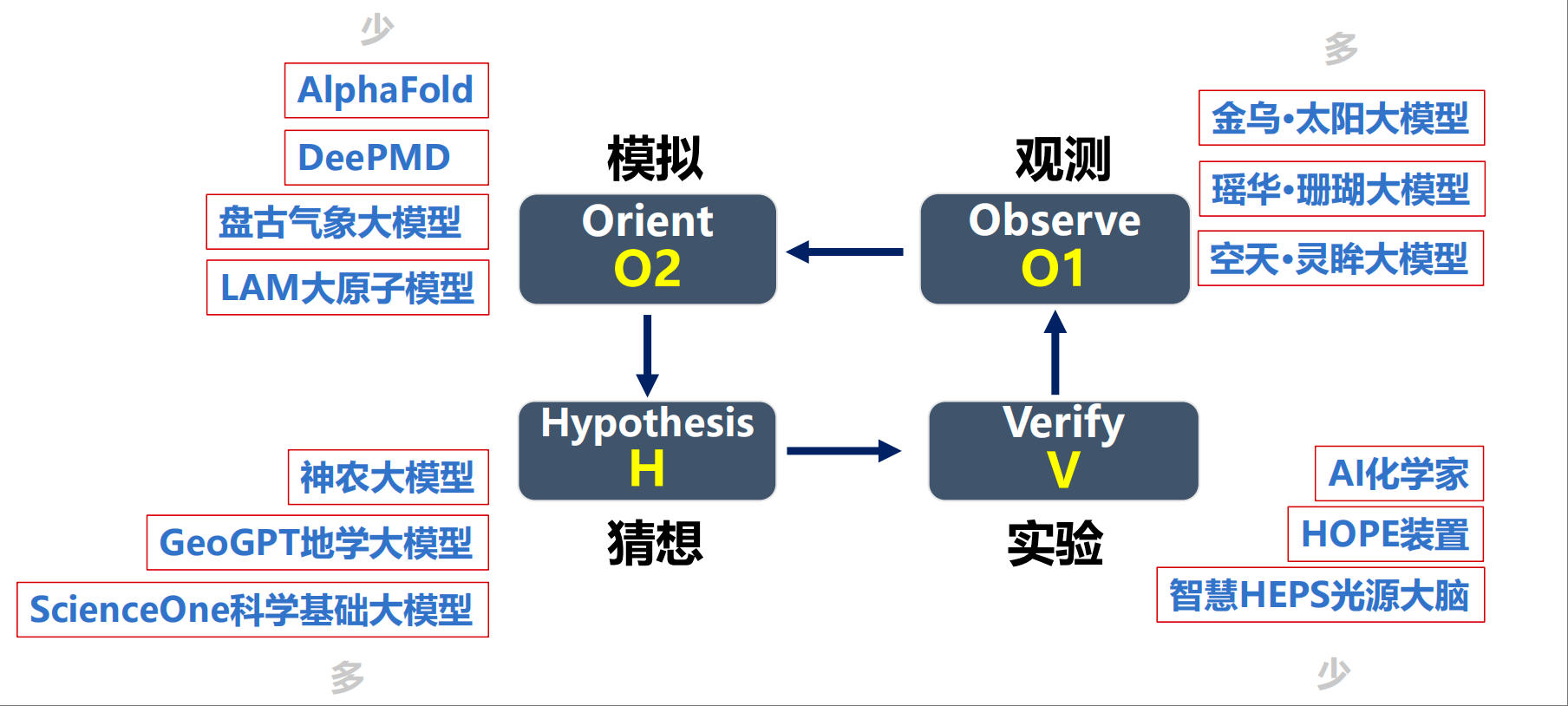 AI4S赋能模拟、观测、猜想、实验4个环节的典型案例。 受访者供图,下同
AI4S赋能模拟、观测、猜想、实验4个环节的典型案例。 受访者供图,下同
?
他举出了一些具体的例子:“已有的AI4S的成果,较多还在(对)猜想和观测环节(赋能),因此基于知识大模型的成果较多,比如农业领域的‘神农大模型’,中国科学院自动化研究所发布的‘ScienceOne科学基础大模型’等,它们可以对观测数据用机器学习的方法(来处理数据、发现新规律);赋能模拟环节的工作还比较少,除AlphaFold之外,还有分子动力学模型DeePMD以及‘盘古气象大模型’和‘LAM大原子模型’等,它们对科学发现的帮助潜力巨大;实验环节结合得也不很多,较知名的有中国科学技术大学推出的‘机器化学家’、中国科学院高能物理研究所上线的‘智慧光源大脑’等。”
从这些具体案例来看,孙凝晖认为,信息学科的主要任务是提供工具,包括提高生产率的科研信息化工具和应用开发中间件;而大模型、机器学习算法等赋予科学家的“相当于是手段的进化”。
对此,他有一个形象的比喻:信息技术赋能科学的手段如同从“增强肌肉(算力)”到“提供营养”(数据),如今正朝着“赋予大脑”(人工智能)的方向进化。
“AI4S更大的作用应该是突破人类认知极限,这也是科学研究的最高追求。”孙凝晖说,人类在科学计算范式(第三范式)和数据科学范式(第四范式)下都有许多突破认知极限的工作,比如通过科学计算,我们既能做公里级精度的中短期天气预报,也能从全球尺度做气候变化的预测;通过数据解析,人类得以从基因组层面认识自己,通过天文望远镜摸到黑洞的“脉搏”。如今,在科学智能范式下,也有突破人类认知极限的工作,比如AlphaFold和DeePMD,且二者的技术路径有所不同。
不过,他提醒,AI工具并不是万能的,科学发现依然离不开高性能计算这一基础手段。同时,在解决实际科学问题时,如何对齐AI4S共性工具的科学语义,将成为关键问题。
AI4S的数据、模型、计算问题,以及未来展望
展望AI赋能科学发现的未来发展,孙凝晖深入剖析了AI4S面临的数据问题、模型问题与计算问题。
“科学数据大概来自4个方面,理论数据、观测数据、实验数据和知识数据,AI4S数据集准备不仅需要长期的积累,还需要关注数据的AI-Ready化与成熟度。”孙凝晖表示,科学数据除了机器学习领域通用的特征化、标签化、流程化以外,还需要应用领域更关注物理性质的铆定、各种尺度的对齐工具,这些工具需要以插件的形式作为通用工具里为科学服务。另外,还要注意数据的误差问题和对齐问题——数据的系统性误差会被AI模型学习到,进而影响模型的精度。
模型方面,孙凝晖提到,OpenAI将实现通用人工智能的路径分为5个阶段:对话者(Chatbots)、推理者(Rensoners)、代理者(Agents)、创新者(Innovators)、组织者(Organizations),这5个阶段对应的AI也依次加入了数据驱动、知识嵌入、物理约束、人机协同、群体智能的能力。目前,AI4S的应用能级正处于“数据驱动+知识嵌入+物理约束”三轮驱动的阶段。
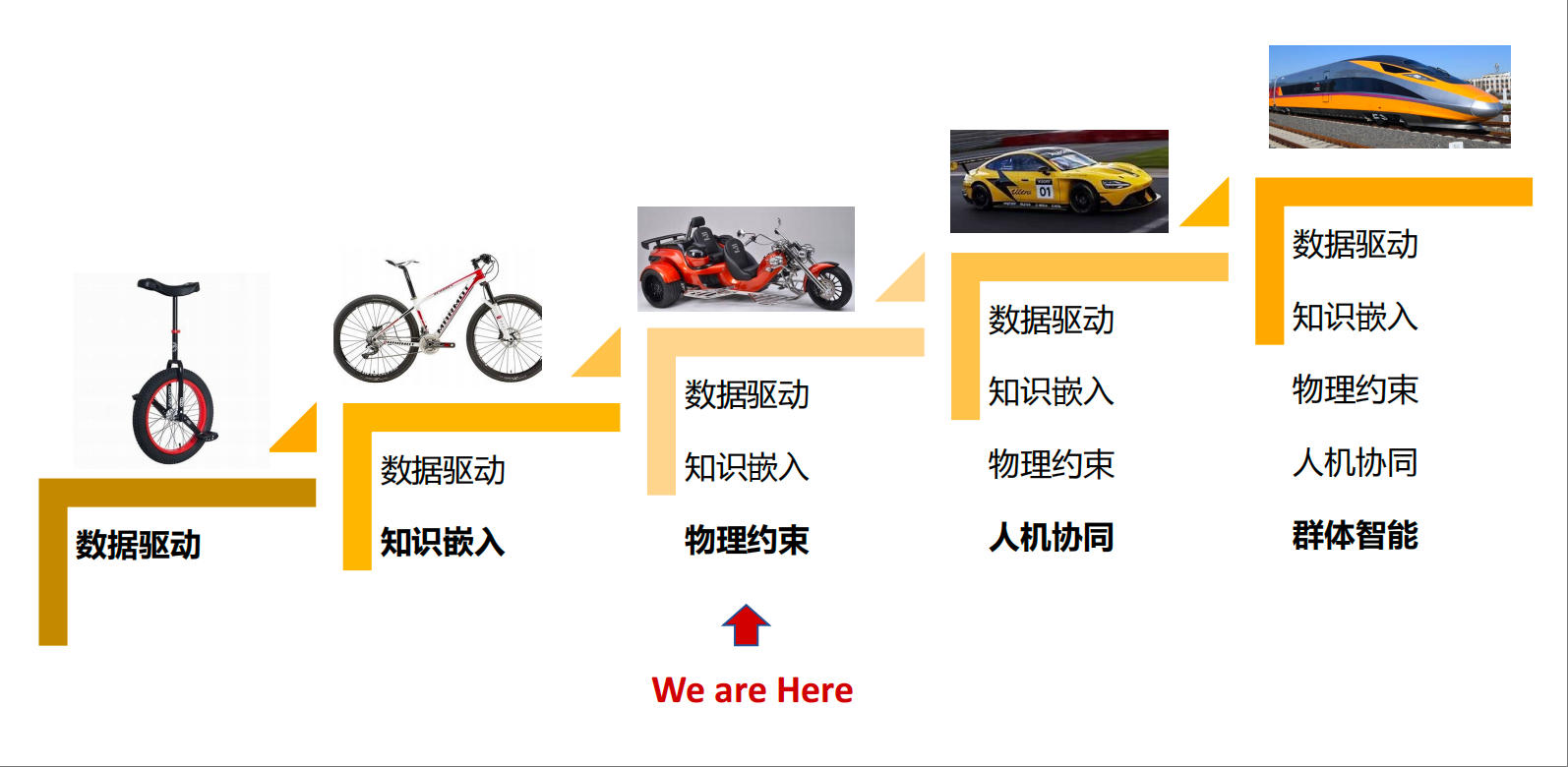 从模型的角度看AI4S的能级。
从模型的角度看AI4S的能级。
?
在孙凝晖展示的AI4S的能级图中,AI的进阶如同从“单车”到“高铁”般地循序渐进:仅靠数据驱动的AI仿佛“单轮车”,随着知识的嵌入,AI成了“自行车”;加入了物理约束(物理性质的铆定、尺度对齐等)后,AI堪比“三轮摩托”。而随着人机协同、群体智能等更多“轮子”的加入,AI有望变成“跑车”“高铁”,将大大加速人类科学发现的进程。
在计算问题上,孙凝晖提到,衡量计算有两个关键维度:精度和架构。科学计算需要高精度,计算系统以异构架构为主;大模型训练也是异构架构,但不需要高精度算力;AI4S不仅需要高(全)精度计算,还需要能够降低负载的融合架构。也就是说,支撑HPC+AI应用的智能超算系统需要8/16/32/64位宽的全精度计算,对系统级互联网络性能的要求也更高,普通的智算中心一般无法满足HPC+AI应用的需求。他表示,未来的智算的融合架构是什么样,这是计算机科学家们需要思考的问题。
孙凝晖展望道,随着算力集群的堆叠、数据来源的多样化、模型参数规模等的进一步提升,未来算力将进化成为Z级(每秒可进行1021次浮点运算)智能超算,数据方面将发展为由海量常识数据、高质量理论数据、实验数据及增强数据来解决更复杂问题,模型上将出现一个参数量超过千亿、通用的科学智能大模型。
而从以往信息技术赋能科学发现催生了计算化学、生物信息学、地理信息系统等学科分支来看,很多人关心,AI4S会不会催生如“智能材料学”这样的新的学科分支?
孙凝晖认为,可以先不着急下结论。能够看到的是,随着AI技术对科学研究范式(如“AI-first”的实验设计)的重构,新的研究工具链(如自动化实验室、AI驱动的仿真系统)的涌现,加之《自然》等顶级期刊开设AI for Science专栏、全球顶尖机构成立AI4S相关或专门的研究单元,一个崭新的AI4S方法论和AI4S学术生态正在形成。
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。






