|
|
|
|
|
提升间歇性备件需求预测精度:一种融合焦点损失与合成少数类过采样技术的新型集成方法 | MDPI Logistics |
|
|
论文标题:Enhancing Intermittent Spare Part Demand Forecasting: A Novel Ensemble Approach with Focal Loss and SMOTE
论文链接:https://www.mdpi.com/2305-6290/9/1/25
期刊名:Logistics
期刊主页:https://www.mdpi.com/journal/logistics
一、引言
备件在工业系统中至关重要,其短缺会导致设备长时间停机,造成重大经济损失;而过量库存则会占用大量资金。间歇性备件需求的特点是长时间无需求期与突发需求峰值交替出现,这种数据失衡使得预测模型难以发挥作用。传统预测方法依赖于难以验证的分布假设,尤其是在处理稀缺事件时效果不佳。为此,本研究提出一种融合合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)和焦点损失(Focal Loss,FL)的新型集成学习模型,以同时解决数据层面和模型层面的不平衡问题。
二、文献综述
间歇性需求预测
现有方法可分为四类:参数方法、非参数非机器学习方法、机器学习方法和混合模型。尽管混合模型展现了优越性能,但多数研究忽视了间歇性需求中的数据不平衡问题。
合成少数类过采样技术
合成少数类过采样技术通过在少数类样本之间进行线性插值生成合成样本,从而平衡数据集。该技术已成功应用于地质、网络安全、金融、医疗诊断等领域,但在间歇性备件需求预测中应用极少。
损失函数
损失函数(Loss Function) 通过量化预测值与真实值之间的差异来指导模型训练。焦点损失通过调整易分类样本的权重,使模型更关注难以分类的样本,从而提升对稀有事件的敏感性。损失函数已在医疗、金融、工业故障检测等领域取得良好效果,但在间歇性需求预测中尚未得到充分探索。
三、研究方法
本研究采用跨行业数据挖掘标准流程(Cross-Industry Standard Process for Data Mining,CRISP-DM) 框架。
1.业务与数据理解:以某大型油气企业为案例,聚焦间歇性备件需求预测问题。
2.数据准备:采用MinMaxScaler对历史数据进行归一化处理,将数据集拆分为需求发生(分类)和需求规模(回归)两部分,采用滑动窗口技术构建序列数据,并应用SMOTE处理类别不平衡。
3.建模:采用两阶段集成策略——分类阶段预测需求是否发生,回归阶段预测需求规模。基础模型包括逻辑回归、决策树、随机森林、支持向量机、轻量级梯度提升机、多层感知器、长短期记忆网络、深度神经网络等。采用堆叠集成方法,以线性回归作为元学习器,并使用遗传算法(Genetic Algorithm,GA)优化集成权重和分类阈值。在深度学习模型的训练过程中,采用焦点损失作为损失函数,以提高模型对难以分类样本的关注度。
4.评估与部署:模型评估采用k折交叉验证法处理时间序列数据,确保性能评估的稳健性和客观性。分类任务使用曲线下面积(Area Under the Curve,AUC),回归任务使用均方误差(Mean Squared Error,MSE)衡量预测误差。评估后模型部署至企业备件库存管理系统,通过自动化流水线处理数据、生成实时预测并集成至运营流程,并持续监控AUC和MSE指标以保障预测可靠性。
四、提出的混合集成模型
模型分为两个阶段:
• 需求发生(分类)阶段:预测给定时期内是否发生需求。使用SMOTE平衡数据,深度学习模型采用焦点损失函数,集成权重和阈值由遗传算法优化。
• 需求规模(回归)阶段:仅当分类阶段预测需求发生时,估计需求数量。使用遗传算法优化集成权重。
最终预测结果为:若分类预测为有需求,则输出回归预测的需求量;否则输出零。
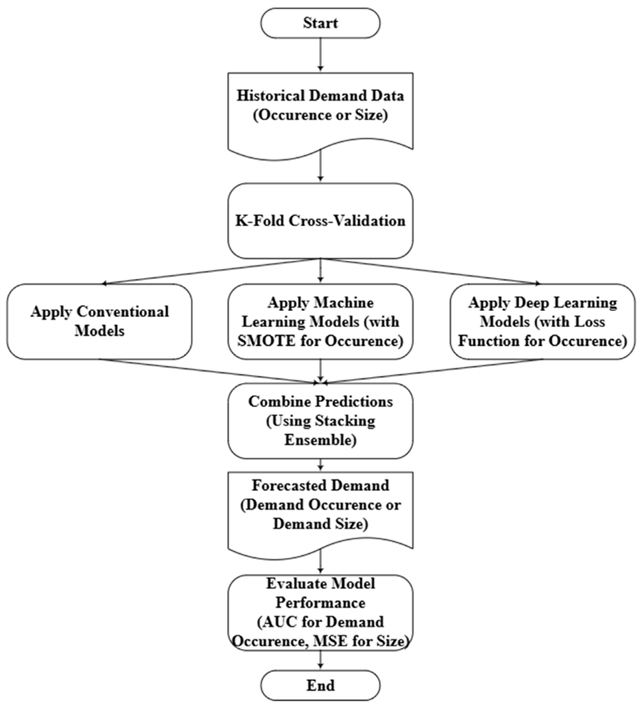
图1:用于推进间歇性备件需求预测的混合集成模型预测阶段的详细框架
五、实验与结果
数据集:收集了2012年1月至2023年12月共624周的备件使用数据。从716个备件中筛选出具有间歇性模式的备件,形成5个数据集,其平均需求间隔(Average Demand Interval,ADI) 介于5.9至209.7之间,平方变异系数(Coefficient of Variation squared,CV²) 介于0.132至0.317之间,反映了不同程度的稀疏性和变异性。
验证结果:提出模型在5个数据集上的AUC 为0.735,显著高于逻辑回归(0.548)、决策树(0.563)、随机森林(0.523)、轻量级梯度提升机(0.718)、长短期记忆网络(0.442)和深度神经网络(0.462)。总体均方误差为3.47,远低于朴素法(8.51)、移动平均(8.31)、自回归积分滑动平均模型(8.04)、K近邻(5.68)、长短期记忆网络(5.69)和轻量级梯度提升机(4.47)。
测试结果:与Syntetos-Boylan近似模型(AUC=0.50,MSE=3.08)、Bootstrap方法(AUC=0.50,MSE=14.25)、堆叠集成模型(AUC=0.64,MSE=4.99)和最佳阈值间歇性需求组合预测模型(AUC=0.50,MSE=3.69)相比,提出模型实现了优越性能。提出模型的AUC平均提升32%,MSE平均降低47%。
六、结论
本研究提出的融合SMOTE和焦点损失的集成模型,在间歇性备件需求预测任务中显著优于传统方法和现有先进模型。该模型对高稀疏性和高变异性的数据集表现出极强的适应能力。本研究的主要局限在于:在较低稀疏性数据集上性能提升相对较小,且模型计算复杂度较高。未来研究方向包括:探索替代重采样技术、自适应损失函数、更高效的优化算法,以及将预测模型与库存管理系统集成。

Supply Chain 4.0: Lean, Agile, Green Practices
投稿截止日期:2027年1月15日
客座编辑:Dr. Sandeep Jagtap, Dr. Rashmi Ranjan Panigrahi, Dr. Subhodeep Mukherjee and Dr. Harshad Sonar
https://www.mdpi.com/journal/logistics/special_issues/6ZC60FD272
期刊介绍
主编:Prof. Dr. Robert Handfield
Logistics(ISSN 2305-6290)是一个为物流和供应链管理领域的研究人员及具有学术倾向的从业者设立的原创性期刊。期刊主要发表与物流和供应链相关的原创文章和高质量综述。主题涵盖领域包括但不限于:人工智能、物流分析和自动化;可持续发展与逆向物流;人道主义和医疗保健物流;最后一公里,电子商务与销售物流;海运物流;供应商,政府和采购物流等。
2024 Impact Factor:3.6
2024 CiteScore:8.0
Time to First Decision:19.6 Days
Acceptance to Publication:4.6 Days
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






