|
|
|
|
|
FCS 联邦推理大模型最新研究综述——迈向数据“深水区”,私域大数据如何助力大模型? |
|
|
论文标题:Federated reasoning LLMs: a survey
期刊:Frontiers of Computer Science
作者:Shuyue WEI, Yongxin TONG, Zimu ZHOU, Yi XU, Jingkai GAO, Tongyu WEI, Tianran HE, Weifeng LV
发表时间:29 Apr 2025
DOI:10.1007/s11704-025-50480-3
微信链接:点击此处阅读微信文章

引用格式:
Shuyue WEI, Yongxin TONG, Zimu ZHOU, Yi XU, Jingkai GAO, Tongyu WEI, Tianran HE, Weifeng LV. Federated reasoning LLMs: a survey. Front. Comput. Sci., 2025, 19(12): 1912613
阅读原文:

“如果说互联网中占比90%以上的私域数据是漫天繁星,那么联邦智能计算就是把点点星光织成银河的丝线。”
互联网公域大数据为大模型扩展定律(Scaling Law)的发现奠定了数据基础;然而,近年来,OpenAI、Anthropic等国际AI的龙头企业,在数次大模型的迭代中已经几乎“吃光”了高质量的互联网公域语料,正遭遇严峻的“数据瓶颈”的挑战。据MIT、Epoch AI等机构的科研人员估计,用于训练AI高质量公域数据将于2028年(4年内)耗尽,如何破局当前大模型的“数据墙”挑战,为其可持续发展提供“数据燃料”迫在眉睫。
为推动激活互联网占比90%以上私域大数据、构建可利用跨域大数据的联邦大模型,北京航空航天大学童咏昕教授团队全面调研了联邦大模型领域的最新研究,聚焦大模型的复杂推理,撰写了首篇联邦推理大模型的综述论文《Federated Reasoning LLMs: A Survey》——从大模型可接受训练信号类型(来自原始数据、学习表征及人类偏好的训练信号)视角出发,剖析了联邦大模型领域的最新技术趋势,展望了联邦大模型领域未来有前景的新赛道,为相关研究者提供了全面且富有前瞻性的技术图景。
1.联邦大模型: “数据墙”的破局之道
近年来,尽管推理大模型成为了解决数学计算、自动编程等强逻辑性推理计算问题的新范式,互联网公域数据枯竭带来的“数据墙”挑战使得推理大模型难以继续沿用原有扩展定律(Scaling Law)的方式提升性能。2024年《Nature》文章指出,来自互联网公域的高质量训练数据即将在2028年耗尽(如图1所示),并认为当前训练语料的“数据饥荒”现状将迫使原有的大模型技术发生重要变革。同样的,2024年底,ChatGPT之父Ilya Sutskever在NeurIPS会议报告中甚至认为当前大模型的预训练范式已经终结。实际上,互联网中可公开的大数据只占其全部数据一小部分。据匿名者(Anonymous)黑客社区估计,互联网中访问受限的私域数据占其全部数据的90%以上。在此背景下,联邦学习以其“数据不动模型动”的计算思想,被广泛认为是一种可克服大数据“自治分散”与“跨域利用”矛盾的分布式机器学习范式。借助联邦学习技术,大模型可以激活互联网私域大数据的能力。因此,联邦大模型正成为破局当前“数据墙”困境的关键。
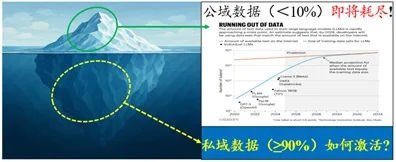
图1:大模型时代下互联网公域/私域大数据的占比和开发情况
2.技术分类:联邦大模型的三类训练信号
与传统小模型不同,大模型所特有的涌现能力、上下文学习能力明显地扩展了其可以接受的训练信号范围。例如,可以使用来自提示词(Prompts)、用户指令(Instructions)和人类偏好(Human Preference)等信号训练大模型,从而增强大模型的垂域推理能力。综述首次根据大模型依赖的训练信号,将当前联邦大模型的训练技术分为三类(如图2):
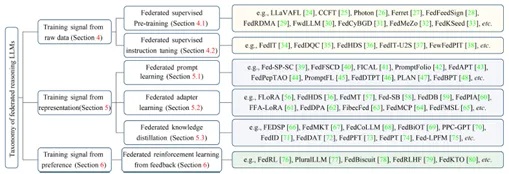
图2:训练信号视角下的联邦大模型的技术分类
1)来自源数据的训练信号。与深度学习时代的机器学习模型训练方式类似,联邦大模型可使用来自原始数据的训练信号(主要是联邦监督学习方法),通过共享梯度参数等方式完成联邦大模型训练。联邦大模型的预训练和指令微调通常使用该类技术。
2)来自学习表征的训练信号。大模型被广泛认为是优秀的零样本/小样本学习器,因此接收学习后得到的模型可解释表征信号,例如提示词(Prompts)、适配器(Adapter)、蒸馏知识(Distilled Knowledge)等,并通过联邦迁移学习技术完成联邦大模型训练。
3)来自偏好反馈的训练信号。在大模型的涌现能力下,其可以灵活地使用高度抽象的人类偏好反馈来完成有效训练。例如,给定大模型生成的两个输出,让用户选择其偏好的输出,并以此作为训练信号优化大模型的输出决策。因此,可以通过联邦强化学习技术,汇聚来自不同机构的大模型用户偏好,完成联邦大模型的人类偏好对齐。
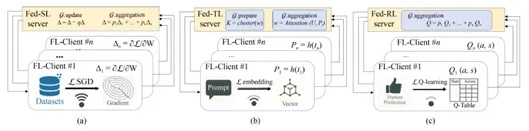
图3:a)原始数据的训练信号 b)学习表征的训练信号 c)偏好反馈的训练信号
3.技术趋势:从联邦学习到联邦大模型
在大数据时代,联邦学习以其“数据不动模型动”的思想避免了传统数据集成直接传输原始数据导致的不可接受的通信开销,成为了跨域大数据智能计算的关键范式。然而,在大模型时代,各个大模型参数规模通常为百亿或千亿级别,所以“模型动”原有思路不再适用于联邦大模型的构建,当前研究正逐渐转向“模型不动知识动”的新技术。针对上述技术转变,该综述总结了联邦大模型中:1)预训练、2)指令微调、3)提示词学习、4)适配器学习、5)知识蒸馏、6)偏好反馈学习的六类技术发展趋势。
1)联邦大模型预训练:该类技术基于原始数据的训练信号,技术发展趋势主要为从基于梯度下降(例如SGD方法)的全梯度参数共享转向可仅传输随机数的零阶优化方法(Zero-Order Optimization),以避免亿级模型参数的传输。以经典的随机两点差分估计为例,其首先随机初始化一组高斯分布的基,并且将梯度值近似写为高斯基下的坐标,在此情况下各方可以仅传输基下的坐标(远远小于模型规模),完成梯度值的近似聚合,从而完成联邦大模型的训练。
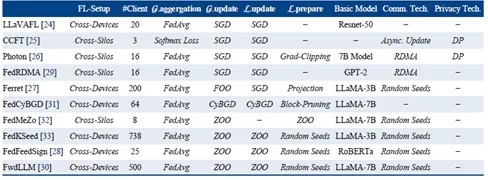
图4:联邦预训练技术的代表性工作
2)联邦大模型指令微调:该类技术基于原始数据训练信号。技术趋势主要为从聚焦数据异质性转向数据多样性感知。在联邦大模型的指令微调中,由于大模型的涌现能力,指令间的异质性不再成为制约其性能的主要瓶颈,能否实行精细化地指令数据优选、尽可能广地覆盖指令类型成为联邦大模型指令微调的关键。
3)联邦大模型提示词学习:该类技术基于学习表征的训练信号,现有工作主要使用两类提示词:原始文本(离散型提示词,Soft Prompts)和嵌入表征(连续型提示词,Continuous Prompts)。其中,嵌入表征相比原始文本通常具有更好的隐私保护效果和更灵活的联邦聚合方法,故现有研究更多倾向于连续型提示词。
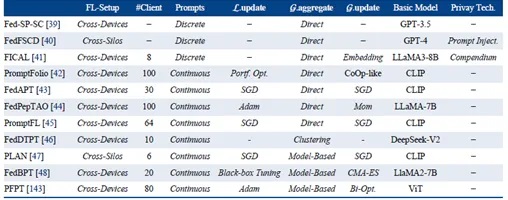
图5:联邦大模型提示词学习技术的代表性工作
4)联邦大模型适配器学习:该类技术在联邦成员间传输适配器(Adapter)进行知识汇聚。大模型的适配器学习旨在通过在模型中增加一小部分参数作为适配器(如低秩近似矩阵)以增强大模型的垂域推理能力。现有联邦大模型研究工作主要采用两种方法:低秩适配方法(Low Rank Adaption, LoRA)和Houlsby适配方法。近来,由于Houlsby适配具有可针对特定下游任务即插即用和更容易集成的特点,能够更灵活地根据下游任务类型和任务域进行推理性能增强,联邦大模型适配器学习的研究逐渐由基于LoRA适配方法转向Houlsby适配方法。
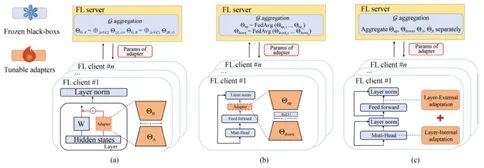
图6:联邦大模型适配器学习技术的示意图
5)联邦大模型知识蒸馏:该类技术在联邦成员间可传输各种类型的模型可接受的信号,包括模型激活值(Activations)、逻辑输出(Logits)、适配器(Adapter)、代理模型(Proxy Models)等。尽管联邦大模型知识蒸馏现有研究采用了多样化表征结果作为联邦训练信号,但是上述表征的适用场景及优劣之处仍有待研究。
6)联邦大模型偏好反馈学习:该类技术基于偏好反馈作为训练信号,主要基于联邦强化学习技术。现有研究根据偏好反馈的提供者可分为:基于人类偏好的反馈学习和基于AI偏好的反馈学习。其中,用户偏好反馈通常受限于用户规模,而且会以侵入式的风格影响用户体验,故现有联邦大模型偏好反馈学习逐渐转向将来自不同域的AI模型作为评估器(Judge),从而通过可扩展性更强、花费成本更低的AI偏好反馈信号,对联邦大模型进行微调与增强。
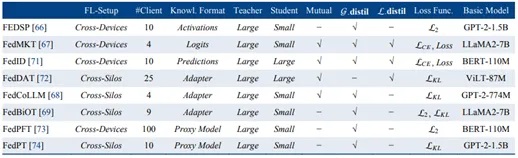
图7:联邦大模型知识蒸馏技术的代表性工作
4.开源平台及典型应用
开源平台:该综述总结了现有联邦大模型代表性开源平台(如图8所示):FATE-LLM、FS-LLM、Shepherd、OpenFedLLM和OpenHufu-LLM等,大部分是在原联邦学习、联邦计算框架基础上升级而来。各联邦大模型开源平台支持的技术如图9所示。
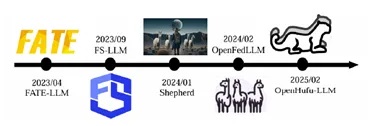
图8:联邦大模型的代表性开源平台
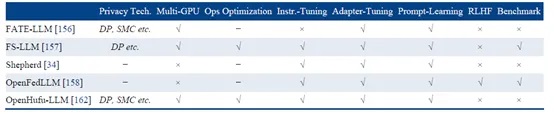
图9 联邦大模型开源平台支持学习方法比较
1) FATE-LLM:该平台基于联邦学习工业级开源平台 FATE 构建,支持联邦大模型的训练与推理中的提示词学习、适配器学习等多种技术,其同样可支持FATE平台中的多种隐私保护技术,包括安全聚合、差分隐私(DP)与安全多方计算(SMC)等。
2) FS-LLM:FederatedScope-LLM (FS-LLM) 提供了指令微调、适配器学习、提示词学习等多种联邦大模型的训练技术,而且其还提供了联邦大模型的基准测试。
3) Shepherd:该开源平台主要面向联邦大模型指令微调技术,并支持数据分配、客户端调度和模型聚合等联邦智能计算的关键技术,从系统层面优化联邦大模型训练。
4) OpenFed-LLM:该平台聚焦于联邦大模型的监督学习和人类偏好反馈学习等技术。与FS-LLM类似,该平台提供了多样化数据集构成的联邦大模型基准测试框架。
5) OpenHufu-LLM: 该平台基于联邦大数据计算平台——OpenHufu,主要从多方通信、分布式GPU调度等系统层面进行了优化,支持了较大规模的联邦大模型参数交换。
典型应用:软件代码生成和健康医疗是联邦大模型的两个典型应用。在软件工程中,由于技术的快速迭代,大量源代码(如工业级源代码)通常以不同版本、风格的语言编写,且往往存储于私有代码库中,无法直接访问。因此,如何构建可支持多风格源代码的代码审查和代码翻译等任务,需联合大量私有代码库构建面向工业代码的联邦大模型。智慧医疗是数据分散自治的典型行业,罕见病诊断等场景依赖于多方医疗数据进行训练。由于医疗数据的隐私敏感性(如患者电子病历、医学影像等)和行业监管要求(如HIPAA、GDPR),高质量临床数据通常分散存储于不同医院和科研机构,且存在数据标准不统一、标注质量参差不齐等问题。因此,如何实现跨机构的疾病诊断、治疗方案生成等任务,需协同多方医疗平台构建面向智慧医疗的联邦大模型。
5.联邦大模型未来研究方向
现有联邦大模型研究在利用不同类型训练信号方面已经取得了显著的进展,联邦大模型在训练和推理两个方面均有值得探索的开放性问题。
1) 联邦大模型的训练赛道: Deepseek-R1等模型的成功证明了大模型可将应用效果作为奖励信号训练大模型。而随着开源大模型被广泛部署,各个大模型的应用方都有着大量的结果数据,联邦大模型则可以联合利用各方大模型使用中产生的应用效果作为训练信号提升大模型的性能。该类应用结果(Outcome Signal)应以何种方式进行联邦聚合,以及是否会泄露原始数据的隐私均是开放性问题。
2)联邦大模型的推理赛道:大模型的上下文学习能力也允许其可通过检索外部公域知识库以增强生成的效果。如上所述,互联网中仍有着大量高价值的私域知识。因此,如何在隐私保护的情况下跨域检索利用私域专业知识,增强联邦大模型的专业能力具有重要意义。该方向包括多方面的开放性问题:首先,联邦大模型的检索生成增强应该选择何种形式的知识(例如原始文本、嵌入表征、代理模型等),以实现兼顾推理效果、通信开销与隐私保护仍待探索;其次,联邦大模型如何设计外部知识的检索路由,以实现所选择推理中必要外部知识的最小化,以降低联邦推理的计算开销,同样是关键问题。
6. 总结
该综述系统地回顾了联邦大模型领域近年来的170篇相关工作,梳理了联邦大模型使用不同类型训练信号的学习方法,聚焦原有联邦学习在适应大模型时代百亿级/千亿级参数特点时的技术变革,并重点关注了联邦大模型的技术发展趋势,构建了联邦大模型的技术全景图。最后,展望了联邦大模型在训练和推理两个技术赛道的未来研究方向。
期刊简介
Frontiers of Computer Science (FCS)是由教育部主管、高等教育出版社和北京航空航天大学共同主办,南京大学支持,SpringerNature 公司海外发行的英文学术期刊。本刊于 2007 年创刊,月刊,全球发行。主要刊登计算机科学领域具有创新性的综述论文、研究论文等。本刊主编为周志华教授,共同主编为熊璋教授。编委会及青年 AE 团队由国内外知名学者及优秀青年学者组成。本刊被 SCI、Ei、DBLP、INSPEC、SCOPUS 和中国科学引文数据库(CSCD)核心库等收录,为 CCF 推荐B类期刊;两次入选“中国科技期刊国际影响力提升计划”;入选“第4届中国国际化精品科技期刊”;两次入选“中国科技期刊卓越行动计划”(一期梯队、二期领军)。

中国学术前沿期刊网
http://journal.hep.com.cn
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






