|
|
|
|
|
南洋理工大学团队创新强化学习算法,为自动驾驶安全决策 “保驾护航” Engineering |
|
|
论文标题:Toward Trustworthy Decision-Making for Autonomous Vehicles: A Robust Reinforcement Learning Approach with Safety Guarantees
期刊:Engineering
DOI:https://doi.org/10.1016/j.eng.2023.10.005
微信链接:点击此处阅读微信文章
新加坡南洋理工大学吕辰研究团队在《Engineering》期刊发表最新成果,提出一种具有安全保证的鲁棒强化学习方法(RRL-SG),为自动驾驶决策的可信性难题提供了创新性解决方案。

随着人工智能和移动通信技术发展,自动驾驶汽车前景广阔,但现实交通场景的不确定性,让确保其决策的鲁棒性与安全性成为巨大挑战。现有自动驾驶决策研究虽有成果,但在应对复杂不确定性时仍显不足。在此背景下,吕辰团队的 RRL-SG 技术应运而生。
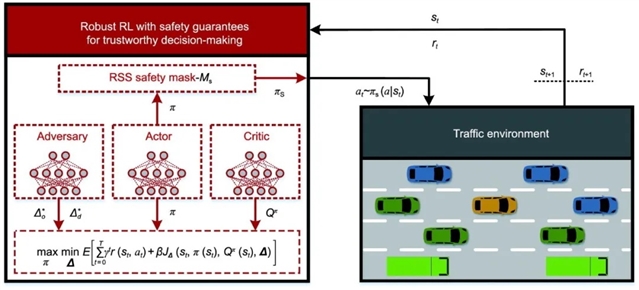
图1 所提出的自动驾驶汽车可信决策的RRL-SG框架示意图。
RRL-SG 技术从策略鲁棒性和碰撞安全性两方面着手。在策略鲁棒性上,团队通过逼近观测状态和环境动态的最优对抗摄动,在线训练对手模型。该模型能模拟最坏情况下的多重不确定性,帮助智能体学习应对观测噪声和环境变化的鲁棒策略。为衡量策略变化,团队利用 Jensen-Shannon(JS)散度设计相关目标函数,优化对手模型参数以确定最优对抗摄动。
碰撞安全性方面,团队借助 Intel 提出的责任敏感安全(RSS)模型开发安全掩码。此掩码依据车辆制动过程和最小安全距离模型,将不安全决策对应的概率设为零,形成安全的动作空间。无论是纵向与前车距离过近,还是横向变道时与邻车距离不足,安全掩码都能及时屏蔽风险动作,保障驾驶安全。
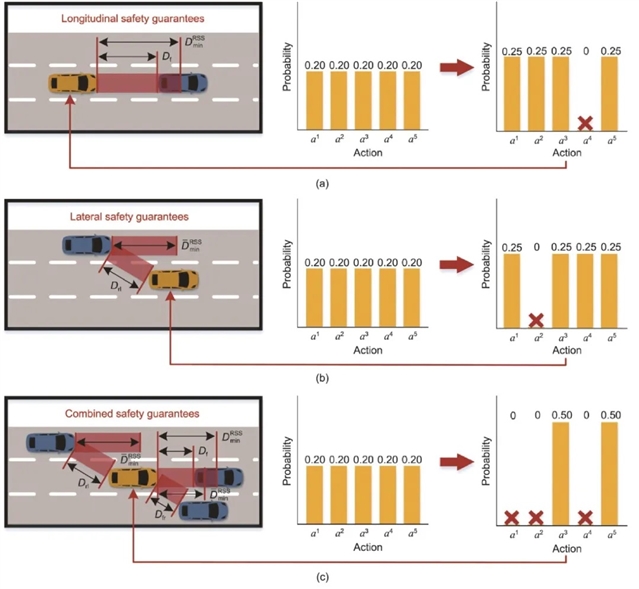
图 2. 基于 RSS 的安全掩码的可信驾驶策略。(a)纵向安全保障示意图。(b)横向安全保障示意图。(c)组合安全保障示意图。
此外,团队还提出对抗鲁棒演员-评论家(ARAC)算法。该算法基于安全鲁棒马尔科夫决策过程,通过安全鲁棒策略评估和策略改进两个阶段的迭代更新,让智能体学习到更优策略。在策略评估阶段,利用增广奖励和两个参数化的行为-价值函数,提高模型训练效率;在策略改进阶段,通过交替优化策略和对抗摄动,并使用双重 Q 技巧减少策略学习误差。
研究团队利用城市交通模拟器 SUMO 进行仿真测试,还使用真实的低速自动驾驶车辆 Hunter 开展物理平台实验。结果令人瞩目:在高速公路和入口匝道合并场景中,RRL-SG 智能体在鲁棒性和安全性上远超 D3QN、PPO、SAC 和 OARL 等基线算法。在 SUMO 仿真中,RRL-SG 智能体在不同密度交通流中,碰撞次数为零,回报率和速度表现更优;在真实实验中,面对对抗性攻击,RRL-SG 策略模型能让车辆保持直线运行,而其他基线模型受影响较大。
吕辰研究团队的 RRL-SG 技术为自动驾驶决策提供了更可靠的方法,然而,目前该技术在为自动驾驶模型的鲁棒性和安全性提供理论保证方面仍存在不足,这也成为未来研究的关键方向。期待该成果能推动自动驾驶技术迈向新高度,让智能出行更安全、更高效。
文章信息:
Toward Trustworthy Decision-Making for Autonomous Vehicles: A Robust Reinforcement Learning Approach with Safety Guarantees
面向可信自动驾驶决策——一种具有安全保证的鲁棒强化学习方法
作者:
何祥坤, 黄文辉, 吕辰*
引用信息:
Xiangkun He, Wenhui Huang, Chen Lv. Toward Trustworthy Decision-Making for Autonomous Vehicles: A Robust Reinforcement Learning Approach with Safety Guarantees. Engineering, 2024, 33(2): 77–89 https://doi.org/10.1016/j.eng.2023.10.005

Open access
开放获取全文
https://www.engineering.org.cn/engi/EN/10.1016/j.eng.2023.10.005
推荐阅读
浙大研究:完全自动驾驶汽车发生事故,乘客要担责吗?
同济大学研究团队:基于安全合理探索与利用的自动驾驶自进化决策规划
清华大学研究团队:通用最优轨迹规划——基于最小作用量原理实现自动驾驶
开放下载:《全球工程前沿2024》完整版
通知:补充征集AI for Engineering专题选题 | Engineering
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






