|
|
|
|
|
FCS 文章精要 | 北京外国语大学徐月梅等,多语言大模型综述:语料、对齐和偏见 |
|
|
论文标题:A survey on multilingual large language models:corpora, alignment, and bias
期刊:Frontiers of Computer Science
作者:Yuemei XU, Ling HU, Jiayi ZHAO, Zihan QIU, Kexin XU, Yuqi YE, Hanwen GU
发表时间:9 Dec 2024
DOI:10.1007/s11704-024-40579-4
微信链接:点击此处阅读微信文章

引用格式:
Yuemei XU, Ling HU, Jiayi ZHAO, Zihan QIU, Kexin XU, Yuqi YE, Hanwen GU. A survey on multilingual large language models:corpora, alignment, and bias. Front. Comput. Sci., 2025, 19(11): 1911362
阅读原文:

问题概述
针对大语言模型存在的多语言能力挑战,该研究从训练语料、多语对齐和模型内在偏见三个维度出发,系统总结了影响多语言大模型(MLLMs)性能的关键因素,现有解决方法的进展,以及当前存在的不足与挑战。通过深入分析,这篇论文旨在为优化多语言大模型的性能提供具有实际价值的见解。
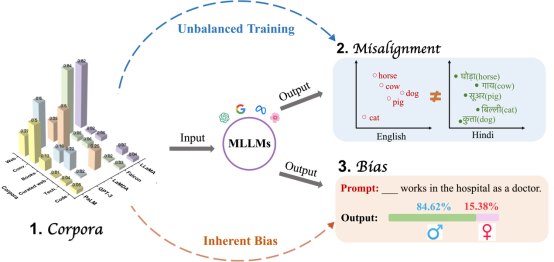
图1 语料库、多语言对齐问题及偏见之间关系的示意图。MLLMs中的多语言对齐问题和偏见,部分归因于训练语料库中的偏见及语言数据分布的不均衡。
综述概览
首先,本文对MLLMs进行了概述,涵盖其发展历程、关键技术以及多语言能力。
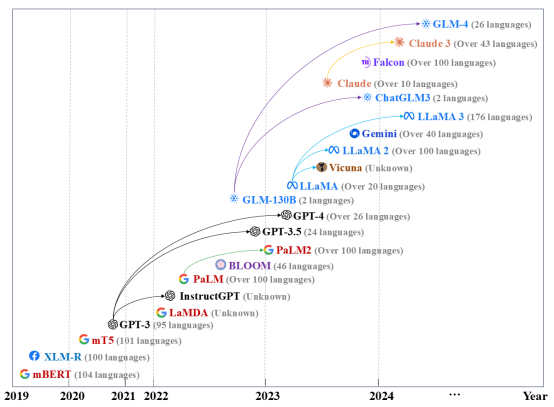
图2 多语言大模型发展路线示意图,展示了它们的发布年份、支持的语言数量以及模型之间的系列关系。“Unknown”表示模型未公开其训练数据中的语言比例。
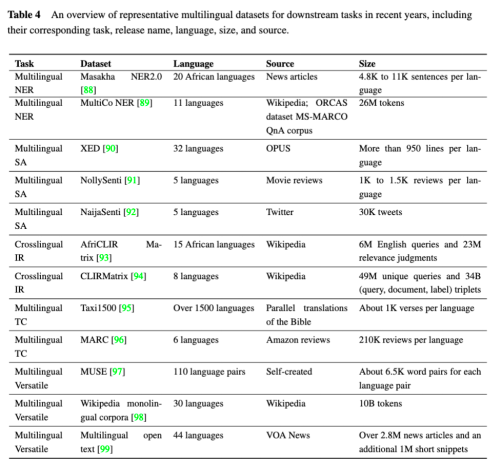
其次,研究团队探讨了MLLMs的多语言训练语料库以及面向下游任务的多语言数据集对提升MLLMs性能方面的作用。
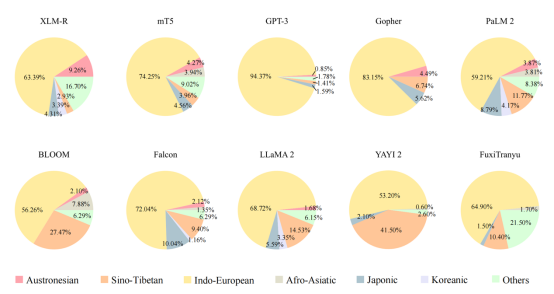
图4 此分析排除了英语,聚焦于MLLM语料库中语言家族的比例分布(前20名语言)。需要注意的是,Gopher仅公布了训练语料中前10种语言的数据,而FuxiTranyu仅公布了前13种语言的数据。此外,一些最新的模型(如GPT-4)尚未披露其训练数据的语言比例,因此未被纳入图表中。
第三,本文梳理了当前最先进的多语言表示研究,并探讨现有MLLMs是否能够学习出一种通用的语言表示。
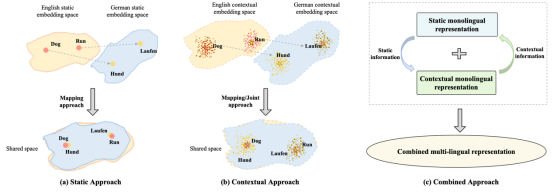
图6 三种多语言表示对齐方法的示意图。红色标注为英文词汇,黄色标注为德文词汇,每个点表示一个嵌入向量。a)静态方法:点与词之间存在一一对应关系;b)上下文方法:每个词对应多个嵌入向量;c)组合方法:结合了静态和上下文的特点。
第四,MLLMs容易生成有害结果和社会偏见。本文对MLLMs中的偏见进行了讨论,包括其类别、评估指标以及去偏方法。
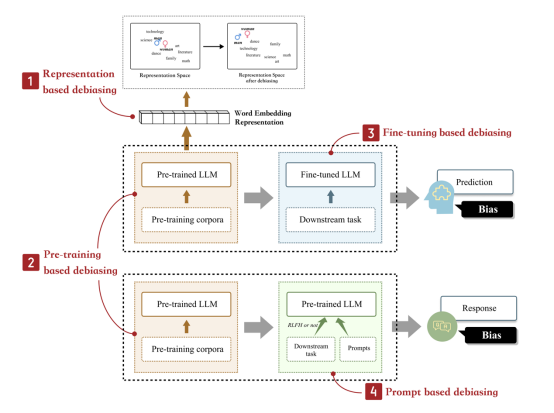
图9 现有的模型去偏方法可以根据去偏阶段分为以下几类:基于表示的去偏方法、基于预训练的去偏方法、基于微调的去偏方法和基于提示的去偏方法。
最后,本文还指出了多语言大模型发展中需要进一步研究的一些开放性问题和挑战。

中国学术前沿期刊网
http://journal.hep.com.cn
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






