|
|
|
|
|
FOE | 前沿综述:迈向忆阻存内计算-从原理到应用 |
|
|
论文标题:Toward memristive in-memory computing: principles and applications (迈向忆阻存内计算-从原理到应用)
期刊:Frontiers of Optoelectronics
作者:Han Bao, Houji Zhou, Jiancong Li, Huaizhi Pei, Jing Tian, Ling Yang, Shengguang Ren, Shaoqin Tong, Yi Li, Yuhui He, Jia Chen, Yimao Cai, Huaqiang Wu, Qi Liu, Qing Wan, Xiangshui Miao
发表时间:22 Jun 2022
DOI:10.1007/s12200-022-00025-4
微信链接:点击此处阅读微信文章

第一作者:包涵
通讯作者:李祎、缪向水
通讯单位:华中科技大学集成电路学院
研究背景
随着大数据时代的到来,传统的冯·诺依曼架构由于处理单元和存储器互相分离,带来了巨大的延时和能耗,承受着高昂的数据传输成本,即冯·诺依曼瓶颈,因此需要对计算架构进行革命性的改变。存内计算(In-memory Computing)范式即是其中一种直截了当的革新方法。顾名思义,存内计算架构在功能和物理上合并了数据处理和存储单元,在数据存储的位置即处理数据,在器件层面以原位的方式执行计算,因此可以避免频繁的数据通信,从而减少相应的延时和能耗。存储器是存内计算的核心器件,存内计算架构的需求同时也促进了新型非易失性存储器(NVM)的发展。模拟式忆阻器作为存内计算的重要器件候选,可以支持各种模拟计算应用,包括人工神经网络(ANN)、机器学习、科学计算和数字图像处理等,展现出了突出的潜力,并亟待后续的进一步研究。
内容简介
本文综述了忆阻存内计算的最新研究进展。作者首先介绍了存内计算的背景,作为其核心器件的忆阻器的基本特性,以及忆阻存内计算范式的基本原理,即通过利用忆阻器的多阶电导调控能力、非易失特性和器件阵列结构,高效率地执行并行矩阵向量乘法(MVM)运算。结合近年来发表的相关工作,作者根据其对计算精度和相应硬件解决方案的不同要求,将它们分为两类,即对不确定、不精准的结果具有容忍性的“软计算”,以及对每个任务都强调明确、精确的数值结果的“硬计算”。作者综述了这两类忆阻存内计算应用的最新进展,其中,软计算部分主要关注神经网络及其它机器学习算法,而硬计算则聚焦于科学计算和数字图像处理算法。此外,作者讨论了尚未解决的开放性挑战,并提出了忆阻存内计算范式的进一步发展方向,希望能引发人们对这一新兴领域的关注,并进一步启发相关的研究成果。
图文简介
内容1 :忆阻器和忆阻存内计算原理
MVM作为最基本和最重要的数学操作之一,是如数字信号处理、机器学习算法和方程求解等诸多应用领域的核心操作步骤。忆阻交叉阵列由于具有完全互联的拓扑结构,可以高并行地执行MVM运算。在忆阻阵列中,输入向量被编码为按时序输入的电压向量,而待运算矩阵则被映射为器件的电导值,通过欧姆定律和基尔霍夫电流定律,运算结果可以直接从忆阻阵列的输出电流中获得。该运算范式具有O(1)的时间复杂度,因而运算时间与矩阵大小无关,相比于传统的CMOS处理器,具有更高的能效,且能消除大量的数据传输开销。然而,作为一种模拟计算范式,忆阻存内计算的结果的准确性直接受限于其硬件特性,包括器件的有限电导态和本征随机性,以及精度有限的数模转换器(DAC)和模数转换器(ADC)。根据不同应用对计算精度的要求,可以被大致分为软计算和硬计算两类,其中软计算对不确定、不精准的结果具有容忍性,而硬计算则强调明确、精确的数值结果。在软计算中,机器学习是最具代表性且最重要的领域之一,通常聚焦于从数据的内在和相对关联中学习一个特定的模型,并实现数据分类、聚类或回归等不同任务。优秀的机器学习算法所必需的泛化能力和鲁棒性天然兼容了软计算结果的模糊性。而在硬计算中,由于微小的中间计算误差仍会导致最终计算结果存在巨大的偏差,因此通常要求运算处理器有极高的计算精度,对硬件实现提出了严峻的挑战。科学计算和数字图像处理将被作为硬计算的代表,介绍其取得的进展,并讨论可以克服的挑战以及提升基于存内计算范式的硬计算性能的最新方法。
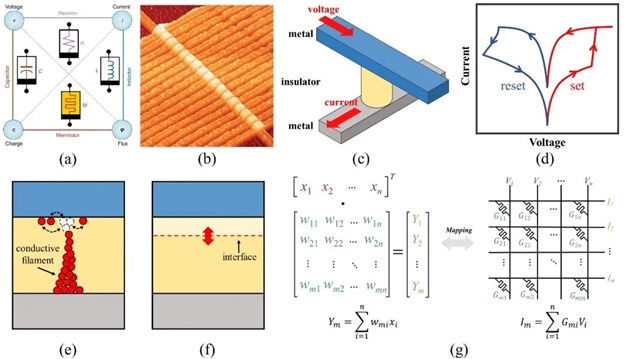
图1. (a) 忆阻器的理论由蔡少棠教授于1971年首次提出,是除电阻、电容和电感之外的第四种基本无源电路元件。忆阻器由磁通量(φ)和电荷(q)之间的关系定义【Nat. Electron, 1(5):322】;(b)惠普实验室于2008年首次制备并展示的忆阻阵列的扫描隧道显微镜图像【Memristors and Memristive Systems, pp. 3–16】;(c)具有金属/绝缘体/金属三明治结构的忆阻器图示;(d)典型的忆阻器I-V曲线示意图,显示了电压扫描下的捏滞回线,表明忆阻器具有可逆的电阻调控能力;(e)导电细丝型和(f)界面型忆阻器的电导调控机理图;(g)基于欧姆定律和基尔霍夫电流定律,将MVM运算映射到忆阻交叉阵列中的原理示意图
内容2. 忆阻神经网络的硬件实现
ANN强大的数据表达能力通常伴随着不断增长的网络参数和计算量的代价。而忆阻神经网络通过忆阻阵列高效的MVM运算,能够实现更快的计算,并减少数据的存储和移动开销,进而完成整个系统加速。从基本的多层感知机(MLP)到卷积神经网络(CNN)模型,再到更为复杂的长短时程神经网络(LSTM)、记忆增强网络(MANN)等,忆阻神经网络推断已经得到了广泛的实现与验证,相较于GPU等处理器能够取得数量级的性能提升。针对CNN的特性,除了通用型的忆阻神经网络加速器,还存在着特殊设计的3D阵列结构,以实现更高的计算密度和效率。
除此之外,忆阻神经网络训练可以使网络适应忆阻器件的非理想效应,如器件间差异性、失效和良率等,且可以在各种实际应用中加强网络的灵活性和通用性。因而有许多研究关注忆阻神经网络训练策略的部署和优化。
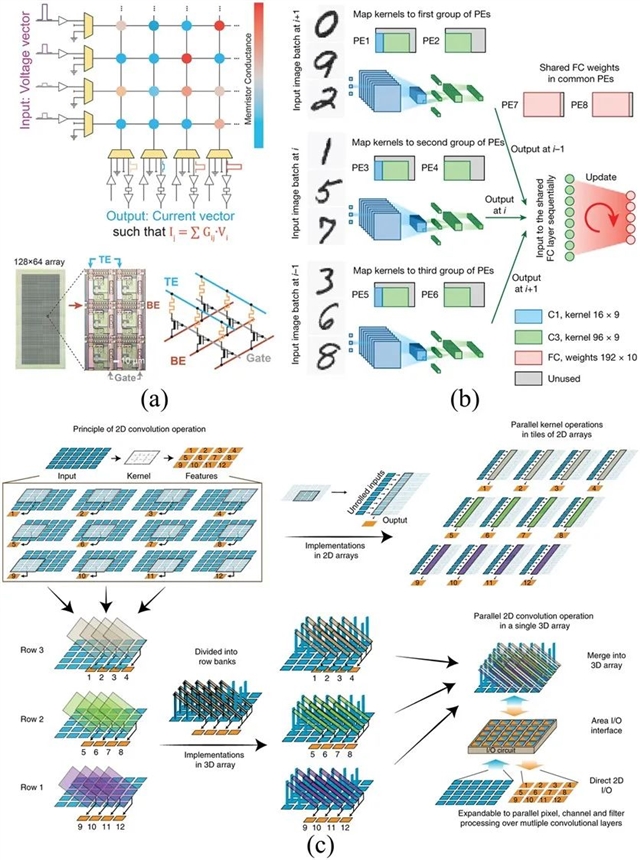
图2. (a)由128×64 1T1R忆阻阵列和外围电路构成的MVM实现方案【Adv. Mater., 30(9): 1705914】;(b)带有复制卷积核和混合训练方法的硬件系统操作流程简图【Nature, 577(7792): 641–646】;(c)在特殊设计的阶梯结构3D忆阻阵列中映射卷积操作的策略示意图。在2D阵列中处理卷积操作需要对权重核和输入信息进行重新排列,而在所展示的3D阵列中则只需要一些简单的移位和复制操作【Nat. Electron., 3(4): 225–232】
内容3. 基于忆阻器的机器学习算法
数据维度的剧增也给传统的机器学习算法带来了巨大的挑战。与直接利用忆阻阵列加速矩阵操作的神经网络应用不同,非神经网络类型的忆阻机器学习算法更多地依赖于特定的数据映射方法或近似计算策略来处理算法中的复杂操作。一类代表性的应用是通过忆阻阵列实现相似度度量。如欧氏距离、余弦距离等的常用的相似度计算方法,常应用于K-means数据聚类、最近邻搜索、自组织映射算法等诸多基础机器学习算法中。许多研究通过优化映射策略和计算方法,在忆阻阵列上实现了高效的存内相似度度量。
另一类处理高维数据的方法是直接利用忆阻阵列提取原始数据的特征并降低数据维数,如主成分分析法(PCA),稀疏编码方法(sparse coding)等。通过在忆阻阵列上存储变换矩阵或是特征字典,这类机器学习算法可以有效地利用忆阻存内计算范式进行加速。此外,兼容适配多种算法的忆阻机器学习加速器也受到了研究者的关注,成功的演示了包括MLP、PCA、稀疏编码在内的多种应用,为面向机器学习的通用硬件加速系统提供了解决方案。
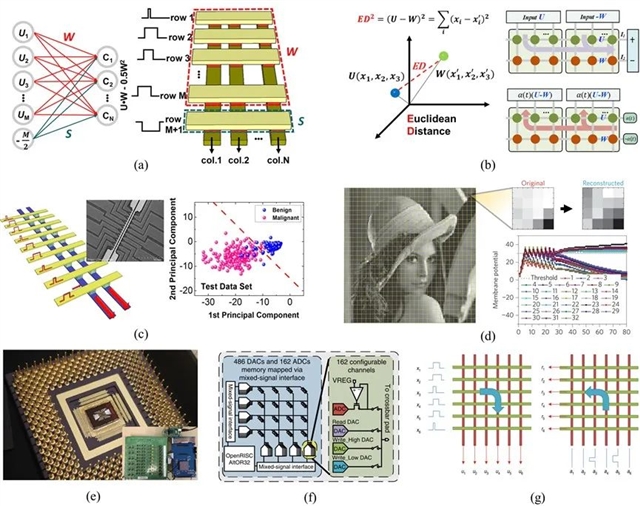
图3. (a)基于忆阻器的K-means聚类算法【Nano Lett., 18(7): 4447–4453】;(b)用于竞争学习的欧氏距离引擎的数据映射方法【Adv. Intell. Syst., 3: 2100114】;(c)基于忆阻器的PCA算法及其在乳腺癌公开数据集上实验验证结果【Nano Lett., 17(5): 3113–3118】;(d)基于忆阻器的稀疏编码方法以及结果【Nat. Nanotechnol., 12(8): 784–789】;(e)一个通用可编程的机器学习算法应用芯片,(f)芯片上可配置的ADC和DAC提供了(g)双向的数据流【Nat. Electron., 2(7): 290–299】
内容4. 利用器件本征随机性解决优化问题的方法
忆阻器内部的本征随机性会给器件的电导态带来无法消除的噪声和扰动。尽管软计算任务可以容忍适当程度的噪声,但在实际应用中,过高的电导随机性仍是难以承受的。然而值得注意的是,电导态的随机分布通常表现出高斯分布的特性,因此可以被用于许多概率计算应用中,将原本有害的噪声利用起来。霍普菲尔德网络(HNN)是解决组合优化问题的常用算法之一,且通常需要采取退火方法来帮助网络收敛到最优解。研究者们一方面通过忆阻阵列的并行计算特性来加速HNN的迭代计算过程,另一方面则通过利用器件的本征读噪声或电导演化的随机性,实现多种高效的退火方法,最终取得更加优秀的网络表现。马尔科夫链蒙特卡洛(MCMC)方法通过数据抽样同样可以用来解决优化问题。在这种方法中,忆阻交叉阵列被用作一个天然的硬件采样机器,阵列中的每一行都对应问题的一种解,而迭代生成的新解则由于器件电导的概率分布而天然具有随机性。
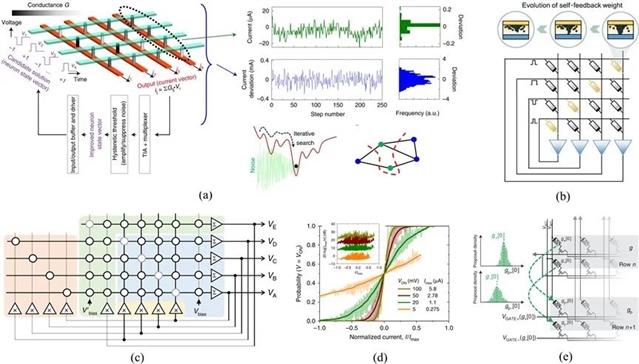
图4. (a)通过外围电路调制器件本征噪声来优化忆阻HNN【Nat. Electron., 3(7): 409–418】;(b)使用对角线上忆阻器件作为自反馈权重的硬件实现TCNN的映射策略【Sci Adv, 6(33): eaba9901】;(c)用于实现广义HNN的多功能随机点积电路。蓝色、黄色、绿色和红色背景分别对应基准HNN,以及随机、可调和混沌方法的实现。标有Σ/×的电路模块表示求和/缩放操作;(d)用于BM网络的随机神经元在不同施加电压(对应不同的等效退火温度)下的传递函数【Nat. Commun., 10(1): 5113】。插图展示了峰值信噪比;(e) MCMC采样方法的演化策略示意图【Nat. Electron., 4(2): 151–161】
内容5. 忆阻存内科学计算
科学计算旨在为科学研究和工程应用中的自然及技术问题进行建模,通常需要具有高计算精度(大于64位浮点精度)、高吞吐量、低延时特性的高性能计算机(HPC),并配合低时间复杂度的数值算法来执行。然而,忆阻存内计算硬件受限于器件非理想效应的限制,通常只能执行低精度计算(≤ 6-bit),且需要复杂的外围电路配合,导致计算延时显著增加。此外,忆阻阵列的全连接特性使其在处理稀疏向量-矩阵运算(SpMV)时效率很低。上述这些因素均限制着高性能存内科学计算系统的发展。因此,研究者们提出了许多最新的解决方案以克服上述挑战:(1)通过引入数字处理器,引入位切片的方法对忆阻阵列精度进行扩展;(2)提出混合精度存内计算架构,利用高精度的数字处理器帮助算法迭代收敛;(3)通过电路设计实现纯模拟计算,消除DAC、ADC等的开销,以接近于O(1)的时间复杂度实现方程求解、矩阵逆求解等科学计算问题;(4)通过矩阵切片、行/列压缩、子块切割等方法,优化稀疏矩阵的映射和计算过程。

图5. (a)位切片方法,以及在基于位片的模数混合系统中求解偏微分方程【Nat. Electron., 1(7): 411–420】;(b)混合精度存内计算系统,以及在混合精度架构中求解矩阵方程Ax=b的流程【Nat. Electron., 1(4): 246–253】;(c)矩阵方程的纯模拟一步求解电路;(d)矩阵特征向量的纯模拟一步求解电路;(c)和(d)引自【Proc. Natl. Acad. Sci. U.S.A., 116(10): 4123–4128】 (e)执行稀疏矩阵乘法的矩阵切片方法【Nat. Electron., 1(7): 411–420】;(f)可扩展的矩阵计算架构【Proceedings of the 2021 on Great Lakes Symposium on VLSI. ACM, 71–76】
内容6. 忆阻存内计算在图像处理方面的应用
数字图像处理包括图像质量提升、特征提取、信息分析、分类和压缩等诸多方面,涉及了大量的MVM操作,如卷积和正交变换等。由于图像处理的数据通常非常庞大,因此,忆阻存内计算在加速数字图像处理方面展现出了巨大的潜力。研究者们利用高性能的多值忆阻器,可以在阵列上并行实现多个图像边缘检测算子,提升检测质量。而3D忆阻阵列也被用于3D医学图像等的检测,极大提升了运算密度。图像压缩作为另一种重要的应用,可以减小图像的存储和传输成本。而由正交变换实现的图像压缩方法,如小波变换(DWT)、离散余弦变换(DCT)等,其数学本质即两次MVM操作。通过将变换矩阵映射到忆阻阵列上,相比于CMOS电路,可以在能效、面积和性能方面得到显著的提升。然而,器件的非理想因素和ADC/DAC的有限精度仍受限了处理图像的质量。此外,研究者们还设计并验证了忆阻存内压缩感知的实现,大幅优化了计算复杂度。
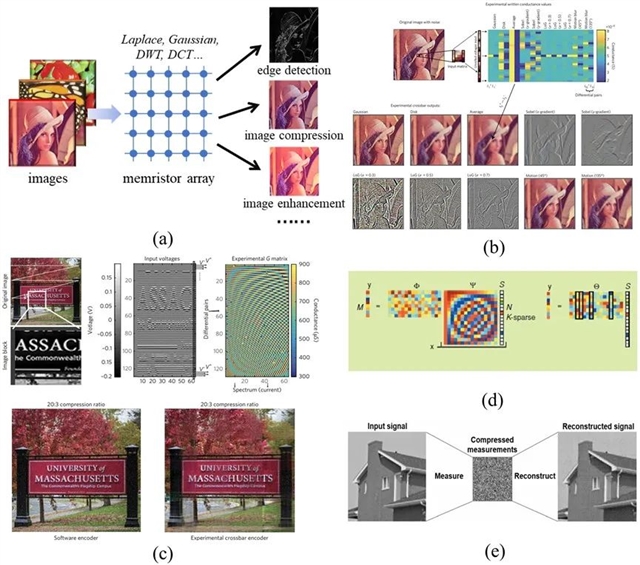
图6. (a)基于忆阻器的图像处理技术;(b)边缘检测和图像滤波的忆阻阵列演示;(c) 2D DCT图像压缩演示;(b)和(c)引自【Nat. Electron., 1(1): 52–59】 (d)压缩感知的基础原理【IEEE Signal Process. Mag., 24(4): 118–121】;(e)压缩感知应用的示意图【IEEE IEDM, 28.23.21–28.23.24】
总结
随着计算机科学和大数据技术的快速发展,传统的冯·诺依曼架构由于处理单元和存储器互相分离,带来了巨大的延时和能耗。忆阻存内计算范式则被认为是有望解决该问题的候选方案之一。以机器学习为代表的软计算应用方向已经在忆阻阵列上得到了广泛的验证,包括神经网络、数据聚类和回归等诸多领域。同时,以科学计算和图像处理为代表的硬计算也成功在忆阻阵列上实现,并在降低功耗和时间复杂度等方面取得了很大突破。究其根本,这些应用的发展都得益于忆阻阵列能够以很高的并行性执行并行矩阵向量乘法操作操作,并消除了大量的数据移动任务。然而,忆阻存内计算仍面临着从底层硬件到系统设计各个层面的不可忽视的挑战。
在器件层面,不同的应用场景对器件的关键特性指标有着不同的需求。对于将运算矩阵映射到忆阻阵列上后便不需要频繁更新的应用,如神经网络推断、科学计算、图像处理等,器件的高精度编程和长时间保持特性是至关重要的因素,而擦写次数则相对无足轻重。但是对于需要经常更新运算矩阵的应用,如神经网络训练等,则严重依赖器件良好的渐变特性和擦写次数。而器件的本征随机性,一方面,可以用于优化任务以及随机计算应用。另一方面,许多机器学习任务可以容忍一定程度上的器件随机性,甚至通过原位训练来补偿一定的误差。与之相反的是,硬计算的任务通常对器件的随机性十分敏感,尤其是科学计算问题,需要严格调控器件的随机性。此外,器件的低电导值、低操作电压以及免初始化过程(forming-free)等特性可以更好的抑制漏电流并提升整体能效,因而符合大部分存内计算应用的发展需求。同时,更大的集成规模和密度,甚至是3D堆叠,也有利于更复杂应用的实现。因此,需要通过机理分析、材料工程、操作方法优化等途径,针对不同应用领域的需求,进行具体的器件性能优化。
在阵列层面,影响存内计算性能表现的主要原因之一是用于阵列内外数据交换的DAC和ADC带来的巨大硬件开销。DAC和ADC的精度越高,意味着模拟计算结果越精确,但也会带来更大的硬件开销,包括能耗、面积和时延,会降低甚至抵消存内计算带来的硬件优势。对于大多数软计算任务,DAC和ADC的精度要求通常可以适当降低。忆阻神经网络推断便通常通过量化算法在较低的精度下执行。对于依赖于精确的MVM计算结果的任务而言,可能的解决方案有几种。一是使用优化的数据复用和数据流策略,并采用特殊设计的ADC/DAC阵列。另一种是通过采用固定化的模拟式外围电路,以纯模拟计算的形式实现一些基础应用,如MLP或一些具有自迭代的科学计算任务。此外,阵列的寄生效应也是阵列层面中面临的重要挑战,如线电阻和寄生电容效应,将导致信号的误差和传输的延迟,且随着工艺节点和集成密度的进一步提升而愈发突出,限制着阵列的大小和并行运行的上限。因此,在硬件设计基础上,对阵列级仿真的深入分析是非常有必要的。
在系统和架构方面,一个突出的制约因素首先是大规模的运算矩阵和现有忆阻阵列的有限规模之间的不匹配。例如,一个50层的ResNet-50网络便拥有超过25Mb的权重,更不用说许多实用化的商业网络模型,而目前最先进的忆阻阵列通常是几个Mb的量级。此外,当考虑一种通用忆阻神经网络芯片,将需要满足多样的互连结构,如残差神经网络(ResNet)的残差连接,LSTM的门控操作,以及CNN中不同粒度的卷积操作等。值得注意的是,除了通用芯片,专用存内计算芯片——就像ASIC之于CPU——也将成为未来的发展主流之一。这些发展方向都对架构设计提出了很高的要求,如分布式计算和资源分配的设计等。其次,对于特定的应用,忆阻神经网络训练在提高灵活性和性能方面表现出了令人印象深刻的潜力,但仍受限于精度和复杂的硬件映射方案。对于科学计算来说,更低的时间复杂度和更高的精度预期可以通过模拟-数字协处理器实现,以及提出更多硬件友好型的存内SpVM策略。除此之外,如何通过融合模拟-数字协处理器和纯模拟处理器结合两者的优势,仍然是一个开放但值得探索的问题。上述各方面都意味着,将硬件映射和软件算法结合起来的跨层级架构设计对于更强大、更高效的忆阻存内计算系统是不可或缺的。
综上所述,相比于传统的计算系统,基于忆阻器的存内计算范式在处理速度和能耗上都带来了很大的优势。作者相信忆阻器和存内计算技术会随着器件到架构层面的发展而不断进步,并最终在物联网和边缘智能领域得到广泛应用。
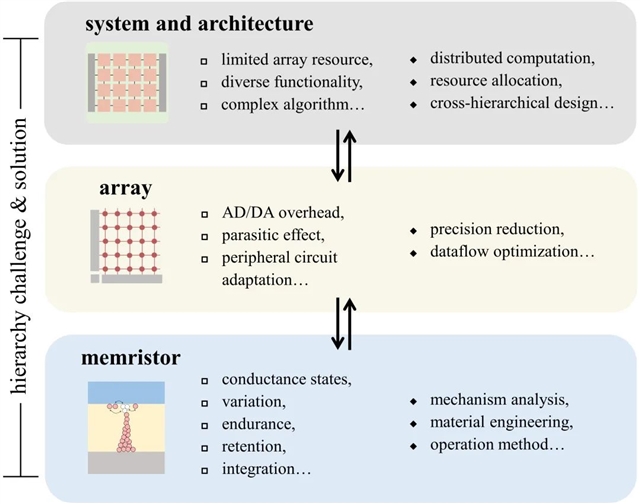
图7忆阻存内计算的挑战和解决方案
作者介绍
李祎副教授,中国科协青年人才托举工程项目入选者,目前就职于华中科技大学集成电路学院。他于2014年在华中科技大学获得微电子学博士学位。他的主要研究兴趣包括忆阻器及其在存内计算与神经形态计算中的应用,相关成果发表在IEEE EDL、TED、TCAS-I、Adv. Funct. Mater.、中国科学·信息科学、IEDM、IMW等重要期刊及会议。
电子邮件:liyi@hust.edu.cn
缪向水教授,教育部长江学者,华中科技大学集成电路学院院长。他于1996年在华中科技大学获得工学博士学位。1996年至1997年,他在香港城市大学任职。1997年至2007年,他在新加坡A*STAR的国家数据存储研究院任职。他的研究兴趣包括相变存储器、忆阻器、神经形态计算和存内计算。他在知名期刊和会议上发表了200多篇论文,包括Science、Nature Communications、Adv. Mater.、Nano Lett.、IEEE EDL、IEEE TED和IEDM等。
电子邮件: miaoxs@hust.edu.cn
团队简介
华中科技大学集成电路学院信息存储材料及器件研究所,密切结合国家及湖北省集成电路产业的重大需求,以存储器领域前沿探索、技术发展以及应用需求为导向,承担了国家02专项、国家重点研发计划、国家自然科学基金等重要科研项目,从原理、材料、器件、工艺、集成、应用多个层面,重点攻关三维相变存储器、忆阻器等下一代先进存储器技术,并在神经形态类脑计算和存内计算等前沿领域开展了一系列引领性工作,研究成果发表在Science,Nature Communications,Adv. Mater,Adv. Funct. Mater., Nano Lett., IEEE EDL, TED, IEDM, IMW等重要期刊和会议。团队多年来和长江存储、华为、武汉新芯等龙头企业开展了密切的产学研合作,为业界输送了一大批优秀人才。
网址:http://ismd.hust.edu.cn/index.htm
摘要
With the rapid growth of computer science and big data, the traditional von Neumann architecture suffers the aggravating data communication costs due to the separated structure of the processing units and memories. Memristive in-memory computing paradigm is considered as a prominent candidate to address these issues, and plentiful applications have been demonstrated and verified. These applications can be broadly categorized into two major types: soft computing that can tolerant uncertain and imprecise results, and hard computing that emphasizes explicit and precise numerical results for each task, leading to different requirements on the computational accuracies and the corresponding hardware solutions. In this review, we conduct a thorough survey of the recent advances of memristive in-memory computing applications, both on the soft computing type that focuses on artificial neural networks and other machine learning algorithms, and the hard computing type that includes scientific computing and digital image processing. At the end of the review, we discuss the remaining challenges and future opportunities of memristive in-memory computing in the incoming Artificial Intelligence of Things era.
期刊简介
Frontiers of Optoelectronics (FOE)期刊是由教育部主管、高等教育出版社出版、德国施普林格(Springer)出版公司海外发行的Frontiers系列英文学术期刊之一,以网络版和印刷版两种形式出版。由北京大学龚旗煌院士、华中科技大学张新亮教授共同担任主编。
其宗旨是介绍国际光电子领域最新研究成果和前沿进展,并致力成为本领域内研究人员与国内外同行进行快速学术交流的重要信息平台。该刊的联合主办单位是高等教育出版社、华中科技大学和中国光学学会,承办单位是武汉光电国家研究中心。FOE期刊已被Emerging Sources Citation Index (ESCI), Ei Compendex, SCOPUS, INSPEC, Google Scholar, CSA, Chinese Science Citation Database (CSCD), OCLC, SCImago, Summon by ProQuest等收录。2019年入选中国科技期刊卓越行动计划梯队期刊项目。

《前沿》系列英文学术期刊
由教育部主管、高等教育出版社主办的《前沿》(Frontiers)系列英文学术期刊,于2006年正式创刊,以网络版和印刷版向全球发行。系列期刊包括基础科学、生命科学、工程技术和人文社会科学四个主题,是我国覆盖学科最广泛的英文学术期刊群,其中13种被SCI收录,其他也被A&HCI、Ei、MEDLINE或相应学科国际权威检索系统收录,具有一定的国际学术影响力。系列期刊采用在线优先出版方式,保证文章以最快速度发表。
中国学术前沿期刊网
http://journal.hep.com.cn

特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。