3月18日,中文大模型测评基准SuperCLUE发布3月报告,该报告显示,豆包、混元、通义千问、DeepSeek-V3位列基础模型国内前四位。
中文通用大模型综合性测评基准(SuperCLUE),是针对中文可用的通用大模型的一个测评基准。它主要要回答的问题是:在当前通用大模型大力发展的情况下,中文大模型的效果情况;包括但不限于:这些模型哪些相对效果情况、相较于国际上的代表性模型做到了什么程度、 这些模型与人类的效果对比如何等。它尝试在一系列国内外代表性的模型上使用多个维度能力进行测试。
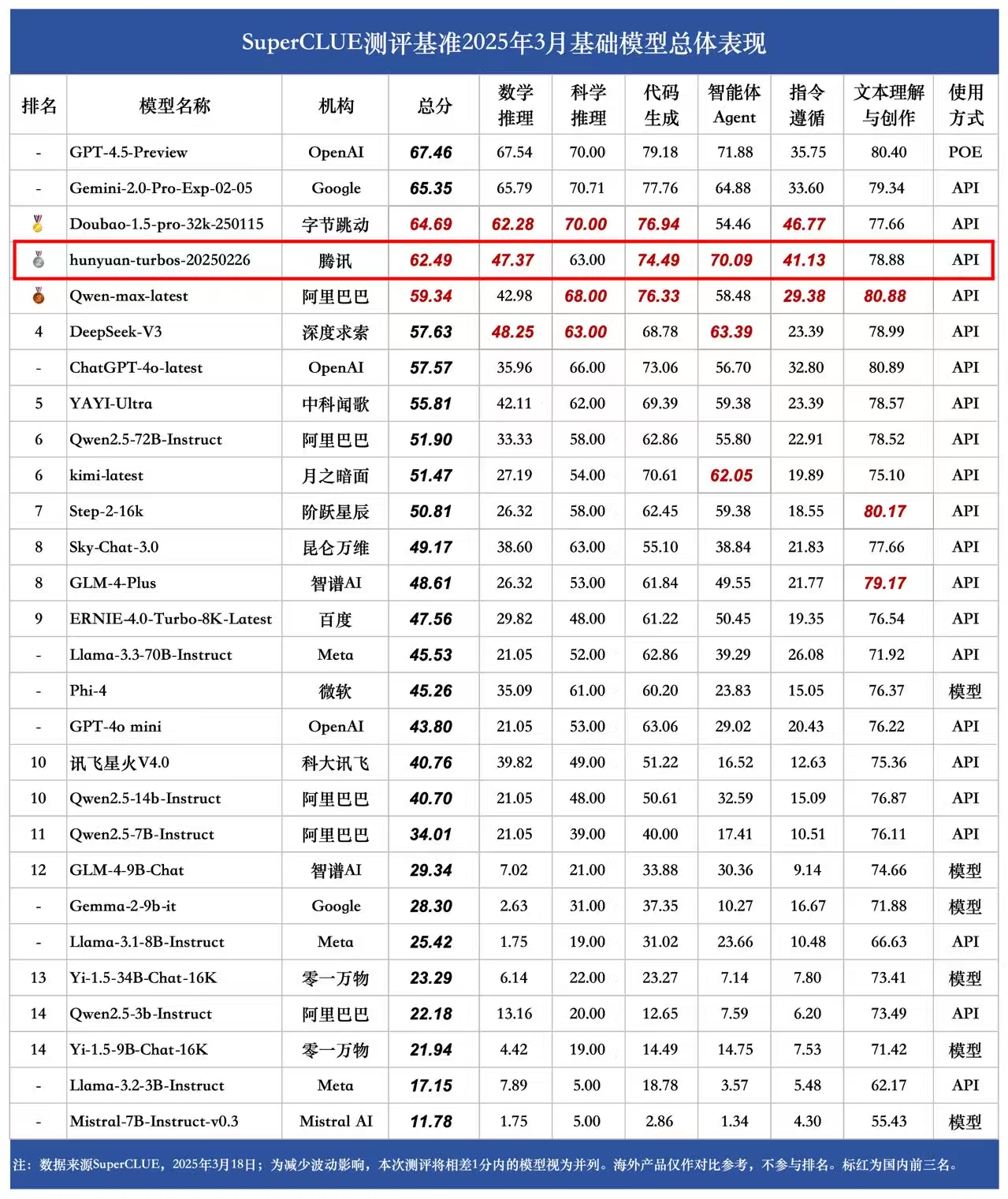 3月排行榜单。截图自SuperCLUE
3月排行榜单。截图自SuperCLUE
?
SuperCLUE最新排行榜单显示,豆包、混元在基础模型排名中表现优异,位列国内前二,稳居国内大模型第一梯队。 在模型象限中,腾讯混元凭借卓越的应用能力排名国内第一,在文本理解与创作、指令遵循以及Agent能力等多个维度刷新最新成绩。在实际应用中,这些能力可以让模型变得更加聪明,更懂用户的问题,从而给出更准确的回复。
另据了解,在海外最新发布的大模型竞技场chatbot arena中,腾讯混元首次上榜,进入全球Top 15,并获官方推荐。据介绍,参与测评的是腾讯混元最新推出的旗舰模型Turbo S,该模型于2月底正式发布,主打快思考,能够更快速输出答案,实现秒回,吐字速度相比前代模型提升一倍。
SuperCLUE榜单链接:
https://mp.weixin.qq.com/s/Nv0YozaCX4cmeiroyq7YEg
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。






