2月24日,记者从华南理工大学获悉,该计算机科学与工程学院教授陈敏团队联合华中科技大学、人工智能与数字经济广东省实验室(广州)在自然语言大模型小样本微调研究领域取得重要突破。他们提出了极具创新性的方案——自然语言微调(NLFT)技术。
该方案以简洁的设计、较低的成本投入,以及准确率提升中的显著成效,大幅降低了大语言模型的准入门槛,摆脱了以往对海量数据和高算力资源的依赖,使得大语言模型更加平民化,使用该技术在单张消费级显卡RTX 4090上跑通的8b微调大模型,可以在使用极少专家数据的前提下获得成倍的性能提升。
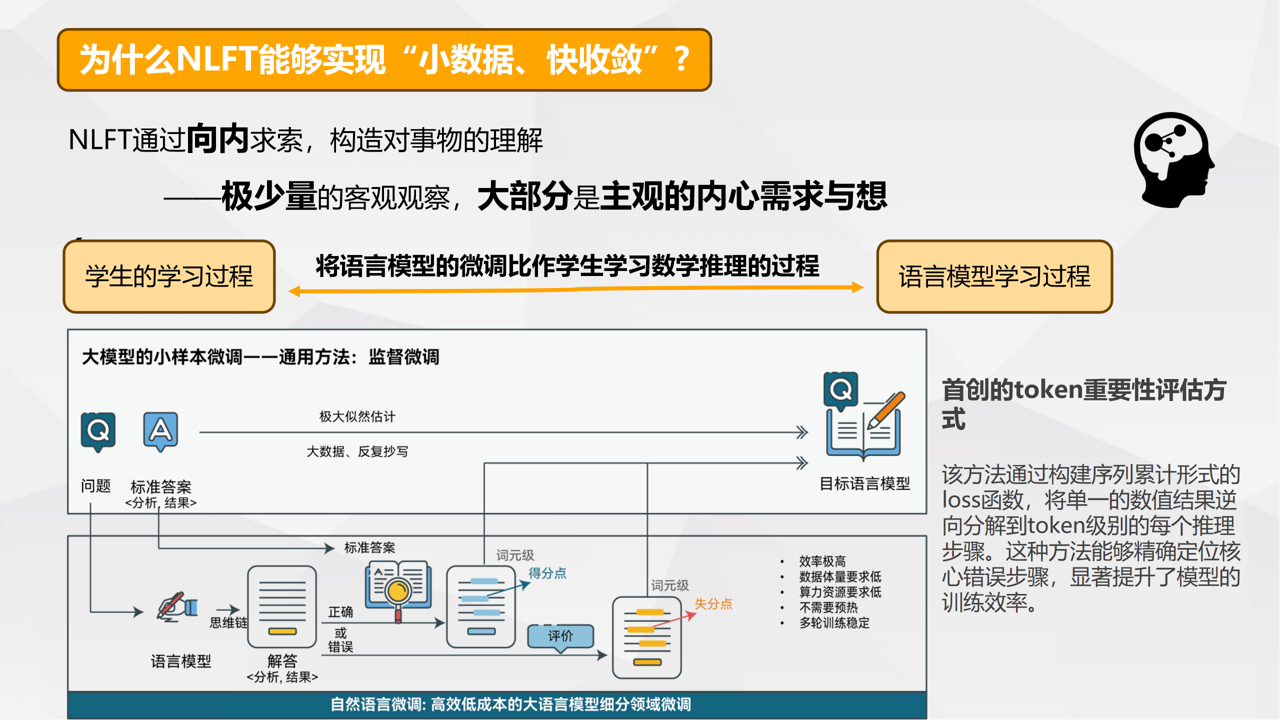 自然语言微调技术(NLFT)的核心理念展示。研究团队供图
自然语言微调技术(NLFT)的核心理念展示。研究团队供图
?
人工智能大语言模型在海量预训练后,往往具备一定的通用能力,而在特定细分领域的表现不尽如人意。为此,陈敏团队提出的NLFT技术为解决该问题提供了新的可能。该技术利用了自然语言作为监督信号,通过条件概率分析和显著性标记分配,对模型进行细粒度优化。
据介绍,与SFT的经典监督学习和字节跳动提出的ReFT采用多阶段预热机制不同,NLFT实现了三大突破:一是,细粒度反馈机制:通过目标模型本身的自然语言理解能力,精准标注每个token的得分点和失分点;二是,零预热学习:NLFT省去ReFT中必需的多轮预训练阶段,直接进行有效微调;三是,充分发挥语言模型能力:研究团队利用目标模型本身作为自然语言评价器,发挥其对语言的深刻理解能力,用可解释性强的方式精准标注,帮助模型迭代进步。
“大语言模型可类比为学生,而大模型微调过程则类似学生的学习过程。”陈敏表示,SFT作为大模型微调的经典技术路线,学生在监督式微调的范式下以鹦鹉学舌的方式学习,即在抄写了大量问题和标准答案对之后,期望学生在看到某些特定问题时能够写下预定的答案。最近,ReFT则也提供了另一种学习范式。
在此范式下,学生首先通过几个周期的监督式微调,将学生“预热”起来,获得解题的基本技巧。然后,为了进一步提高技巧,学生会提交包含引导问题解决方案详细分析的“答卷”。通过与标准答案比较,每份“答卷”获得一个总的分数,通过分数学生调整数学推理的策略,通过强化学习机制习得推理能力,通过多轮提交“答卷”,从评估系统中获得反馈。而在NLFT中,学生通过从详细批改出得分点与失分点的答卷中学习。
据介绍,NLFT技术省去了基于强化学习的微调技术的“预热”环节,学生直接提交“答卷”。通过将目标模型自身作为自然语言评价器,可以实现对学生的答题过程细粒度的分析,标注出得分点与失分点,通过内部指导得到学习。
利用首创的token重要性评估方式,NLFT技术能实现“小样本、快收敛”。NLFT通过向内求索,构造对事物的理解——极少量的客观观察,大部分是主观的内心需求与想象。例如,在数学推理任务上,仅用随机25条训练数据、8轮训练、7分钟、单卡4090,就将准确率只有28.13%的基础LLM的准确率提升到62.03%。该方法通过构建序列累计形式的loss函数,将单一的数值结果逆向分解到token级别的每个推理步骤。这种方法能够精确定位核心错误步骤,显著提升了模型的训练效率。
值得一提的是,2024年12月29日,陈敏团队在GitHub上开源了所有相关代码、数据和模型,并积极寻求在不同领域的泛化应用,以推动该技术的广泛应用和进一步发展。当前,研究团队正在积极开展领域微调的泛化研究,探索其在多个应用领域的潜力。
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。






