|
|
|
|
|
FCS|前沿研究:知识图谱中的实体集扩展:异质信息网络的视角 |
|
|
论文标题:Entity set expansion in knowledge graph: a heterogeneous information network perspective
期刊:Frontiers of Computer Science
作者:Chuan SHI, Jiayu DING, Xiaohuan CAO, Linmei HU, Bin WU, Xiaoli LI
发表时间:15 Feb 2021
DOI: 10.1007/s11704-020-9240-8
微信链接:点击此处阅读微信文章
原文信息
• 标题:
Entity set expansion in knowledge graph: a heterogeneous information network perspective
• 原文链接:
https://journal.hep.com.cn/fcs/EN/10.1007/s11704-020-9240-8
• 引用格式:
Chuan SHI, Jiayu DING, Xiaohuan CAO, Linmei HU, Bin WU, Xiaoli LI. Entity set expansion in knowledge graph: a heterogeneous information network perspective. Front. Comput. Sci., 2021, 15(1): 151307
1.导读
任务
实体集扩展(Entity Set Expansion, ESE)旨在利用少数种子实体找出更多属于某一特定类别的实体。例如,给定几个种子实体,如"纽约"、"华盛顿特区"和"芝加哥"(美国的城市),ESE是为了发现这些实体之间潜在的联系,并获取更多同一类的实体,如"休斯顿"和"洛杉矶"。ESE可以应用于很多任务,如字典构建、词义消歧、查询改进和查询建议等等。
主要问题与挑战
• 面向大规模知识图谱(如Dbpedia),如何有效地找出知识图谱中两个种子实体之间的所有元路径?
• 在知识图谱中,由一个关系连接的两个实体通常存在多种类型,这会导致歧义。如何在知识图谱获得细粒度的元路径捕捉种子实体的内在关系,同时避免引入太多噪音?
• 元路径表示了种子实体间存在的隐藏关系。给定一条元路径,如何衡量候选实体和种子实体的相关性?给定多条元路径,如何衡量不同路径的权重以及学习不同元路径的权重?
主要贡献
• 提出了一个基于CoMeSE的扩展模型CoMeSE++,它同时结合了知识图谱的结构信息和维基百科的文本信息;
• 提出了多类型元路径MuTyPath,它可以更准确地代表种子实体之间的潜在联系,以避免实体集扩展中产生过多的假阳性结果;
• 在真实世界的数据集上进行了广泛的实验,实验结果表明提出的模型在实体集扩展任务上取得了SOTA表现。
2.名词解释
异构信息网络(Heterogeneous Information Network, HIN)是一种由异构信息构成的有向图,其中的节点和边拥有一种或多种类型。在本文中,作者将知识图谱看作是一种异构信息网络。
元路径(Meta Path)是指在HIN中连接两个节点(实体)的类型信息构成的路径,元路径可以用于表示实体之间存在的潜在联系。一条元路径可以由公式(1)定义:
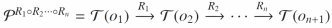 (1)
(1)
其中 表示的是实体
表示的是实体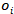 的一个唯一类型,
的一个唯一类型,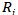 表示的是关系类型。元路径描述了一条两个实体类型
表示的是关系类型。元路径描述了一条两个实体类型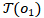 和
和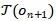 之间的路径,该路径由一系列实体类型
之间的路径,该路径由一系列实体类型 和一系列的关系类型
和一系列的关系类型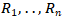 描述。
描述。
3.主要方法
基于双向随机行走的元路径生成方法
元路径能够捕捉HIN中节点之间潜在的语义关系,因此可用于实体集的扩展。但是大规模知识图谱抽取元路径并非易事。为此,作者设计了一种基于双向随机行走的元路径生成方法(bidirectional Random Walk based Concatenated Meta Path generation method,RWCP)。在该算法中,作者将种子实体集两两分对,为每个实体对设置两个行走者从实体对两端开始行走。在行走过程中,算法会生成一条条记录(Recorder)来保存行走者走过的路径、当前路径的重要性得分 以及到达实体集(Arriving entity set),路径重要性得分用于指示该路径的处理优先级,由公式2计算:
以及到达实体集(Arriving entity set),路径重要性得分用于指示该路径的处理优先级,由公式2计算:
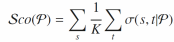 (2)
(2)
其中,s和t分别是元路径p中的源实体和到达实体,k是到达实体的数量, 是基于p计算的相似度,由3.3节介绍的元路径相似度度量算法MuTySim计算。
是基于p计算的相似度,由3.3节介绍的元路径相似度度量算法MuTySim计算。
在生成元路径的过程中,RWCP维护一个记录器集(Recorder Set,RS)用于保存所有生成的记录,一个扩展集(Extension Backlog,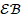 )用于保存待扩展的记录与对应路径的重要性得分,以及一个聚合集(Concatenation Backlog,
)用于保存待扩展的记录与对应路径的重要性得分,以及一个聚合集(Concatenation Backlog,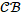 )用于保存待聚合的记录对以及记录对的平均得分
)用于保存待聚合的记录对以及记录对的平均得分 ,由待聚合记录对的平均值计算。
,由待聚合记录对的平均值计算。
通过比较和,RWCP决定是进行路径聚合还是路径扩展。如果中最大值大于 中最大值,RWCP会从取出该记录对,如果记录对中这两条路径的到达实体集有公共实体,那么将生成一条完整的元路径。当为空或中的最大值小于中的最大值时,RWCP从取出最高对应的记录进行扩展(从到达实体集中选择实体来扩展路径),以生成新的记录以及记录器对。RWCP通过迭代地进行记录扩展与聚合来获取元路径,直至,和全部为空。算法1展示了RWCP的具体流程。

算法1:RWCP的具体算法流程
多类型元路径
传统的元路径只会为每一个实体分配一个类型,这并不能准确描述种子实体之前的潜在联系,进而存在生成假阳性实体的问题。为解决这一问题,作者提出了一种多类型元路径(Multi-type meta path, MuTyPath),它是一种特殊的元路径,其中每个实体对象都由该实体的类型集合约束而不是单一类型。一条多类型元路径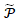 可以由以下公式定义:
可以由以下公式定义:
 (3)
(3)
与普通元路径的区别是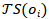 表示的是
表示的是 的类型集合,而不是单个路径。当中的所有实体类型集合的大小都为1时,该路径会退化为普通的元路径。
的类型集合,而不是单个路径。当中的所有实体类型集合的大小都为1时,该路径会退化为普通的元路径。
以下图为例,我们的目标是找到像Steve Jobs和Bill Gates同类的实体,如果使用传统的元路径 来表示实体间的隐藏关系,可能会包含引入错误的实体如Vicent van Gogh。但是使用多类型元路径
来表示实体间的隐藏关系,可能会包含引入错误的实体如Vicent van Gogh。但是使用多类型元路径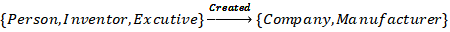 就能够将种子实体间隐藏关系表示的更加准确。
就能够将种子实体间隐藏关系表示的更加准确。

图1:多类型元路径例子
基于多类型元路径的相似性度量
在获取多类型元路径后,就可以基于元路径来衡量候选实体与种子实体之间的相似性了。为此,作者提出了一种基于多类型元路径的相似性度量方法(MuTySim)。
对于只包含单个实体的路径 ,在计算自相似性时,MuTySim考虑到了两个实体类型集的相似性,计算公式如下:
,在计算自相似性时,MuTySim考虑到了两个实体类型集的相似性,计算公式如下:
 (4)
(4)
对于实体s和t,以及元路径 ,考虑到两端实体的入度、出度以及多类型的限制,两个实体对于路径
,考虑到两端实体的入度、出度以及多类型的限制,两个实体对于路径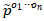 的相似度计算公式如下:
的相似度计算公式如下:
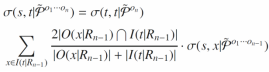 (5)
(5)
其中,x是尾实体t基于关系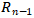 的入连接到达的实体,
的入连接到达的实体,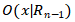 是实体x基于的出连接的实体集合,
是实体x基于的出连接的实体集合,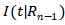 是t基于的入连接的实体集合。
是t基于的入连接的实体集合。
当两个实体s和t由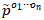 连接,且连接处为实体x,那么s和t的MuTySim相似度由公式6计算:
连接,且连接处为实体x,那么s和t的MuTySim相似度由公式6计算:
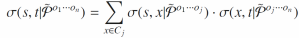 (6)
(6)
其中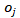 是由实体x确定的位置,
是由实体x确定的位置,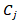 是在位置的实体集合。
是在位置的实体集合。
多类型元路径间的权重学习
在两个实体间如果存在多条多类型元路径,那么不同的元路径间应赋予不同的权重,最终的候选实体c与种子实体s相似度应当为两实体间不同元路径相似度的加权和,由公式7计算:
 (7)
(7)
其中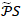 是元路径集合,
是元路径集合,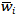 是路径
是路径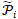 的权重。 为了解决只有正样本(种子实体)场景下不同元路径权重学习的问题,作者提出了启发式学习与PU学习(Positive-unlabeled learning)两种方法。启发式学习为相似度更高、连接更多种子实体对的元路径分配更高的权重,PU学习则通过发现可信的负样本来训练Adaboost分类器。
的权重。 为了解决只有正样本(种子实体)场景下不同元路径权重学习的问题,作者提出了启发式学习与PU学习(Positive-unlabeled learning)两种方法。启发式学习为相似度更高、连接更多种子实体对的元路径分配更高的权重,PU学习则通过发现可信的负样本来训练Adaboost分类器。
候选实体排序
为了进一步提高ESE的性能,作者提出了一个基于CoMeSE的扩展模型CoMeSE++,除了知识图谱中的结构信息以外,该模型还包含了维基百科中实体的文本信息。对于每个实体,作者将其表示为其维基百科文章摘要中的平均词嵌入。词嵌入是以所有维基百科文章为语料训练word2vec得到的。获取到实体的低维表示后,作者以余弦相似度作为实体的文本相似度。最后,候选实体与种子实体的相似度由基于元路径的结构相似度和文本相似度加权平均:
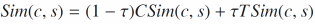 (8)
(8)
其中c是候选实体,s是种子实体,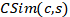 和
和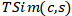 分别是基于元路径的结构相似度与基于维基百科的文本相似度。
分别是基于元路径的结构相似度与基于维基百科的文本相似度。
最后,对于每一个候选实体,计算其与种子实体集中每个种子实体的相似度并求和,作为最终的候选实体排序依据:
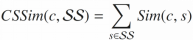 (9)
(9)
其中 表示种子实体集。
表示种子实体集。
4.实验
数据集介绍
在实验中,作者以Yago的两个子集“COREFact”与“yagoSimpleTypes”作为知识图谱进行实验,包含了440多万条事实三元组,35个关系,130多万个实体以及对应的3,455种类型,具体信息如下表所示。
表1:相关数据集的统计结果表

作者选择了四个有代表性的ESE任务来全面评估CoMeSE++的性能。这些任务包括:(1)公司集扩展,种子实体是在美国拥有频道的公司;(2)作家集扩展,种子实体是毕业于纽约大学的作家;(3)演员集扩展,种子实体是获得艾美奖的演员,同时他们的配偶也是演员;(4)电影集扩展,种子实体是国家电影奖得主导演的电影。这四个任务的实际实例数量分别为76、60、193和653。
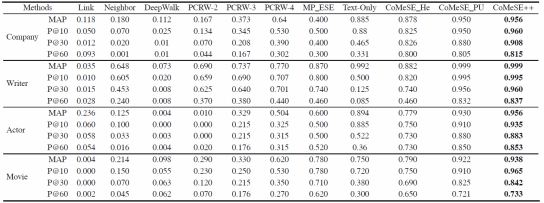
实验结果与分析
下表展示了作者在不同设置下的实验结果。其中CoMeSE_He与CoMeSE_PU表示使用启发式方法和PU学习方法进行权重学习的模型,由于CoMeSE_PU比CoMeSE_He表现更好,作者在CoMeSE_PU的基础上加入了基于维基百科中实体文本信息相似度的计算,在表中对应CoMeSE++。在与基准方法以及CoMeSE的不同设置进行对比后可以看出,元路径的多类型约束以及文本相似度的加入在提高ESE任务的表现上起到很大帮助。
表2:相关实验结果图
下表展示的是在公司实体集任务上抽取的多类型元路径以及对应的权重,可以看到权重最高的路径能够准确的表示种子实体间的关系,也就是这些公司在相同的国家都拥有频道。与传统方法相比,CoMeSE抽取的路径能更好的帮助用户理解实体扩展背后的逻辑。
表3:相关多类型元路径抽取结果及对应权重分析

此外,作者也通过与单类型元路径的对比实验验证了使用多类型路径对实体集扩展的有效性,对比如下表所示。
表1:对比实验分析

5.结论
在本文中,作者在CoMeSE的基础上提出了CoMeSE++,它结合了基于知识图谱的结构信息和基于维基百科的实体文本信息来进行实体集扩展。为了解决实体集扩展任务的难点,作者提出了细粒度的多类型元路径(MuTyPaths),一种基于双向随机行走的算法来快速提取KG中的MuTyPaths,一种新的基于MuTyPath的实体相似度函数(MuTySim)以及路径权重学习方法。通过大量的实验,作者验证了CoMeSE++方法的有效性和效率。通过CoMeSE++,我们也可以看出融合多模态信息来增强语义,正在成为自然语言理解、知识图谱以及相关任务研究的新范式。
摘要
Entity set expansion (ESE) aims to expand an entity seed set to obtain more entities which have common properties. ESE is important for many applications such as dictionary construction and query suggestion. Traditional ESE methods relied heavily on the text and Web information of entities. Recently, some ESE methods employed knowledge graphs (KGs) to extend entities. However, they failed to effectively and efficiently utilize the rich semantics contained in a KG and ignored the text information of entities in Wikipedia. In this paper, we model a KG as a heterogeneous information network (HIN) containing multiple types of objects and relations. Fine-grained multi-type meta paths are proposed to capture the hidden relation among seed entities in a KG and thus to retrieve candidate entities. Then we rank the entities according to the meta path based structural similarity. Furthermore, to utilize the text description of entities in Wikipedia, we propose an extended model CoMeSE++ which combines both structural information revealed by a KG and text information in Wikipedia for ESE. Extensive experiments on real-world datasets demonstrate that our model achieves better performance by combining structural and textual information of entities.
解读:王昊奋 同济大学
审核:张琨 合肥工业大学

Frontiers of Computer Science
Frontiers of Computer Science (FCS)是由教育部主管、高等教育出版社和北京航空航天大学共同主办、SpringerNature 公司海外发行的英文学术期刊。本刊于 2007 年创刊,双月刊,全球发行。主要刊登计算机科学领域具有创新性的综述论文、研究论文等。本刊主编为周志华教授,共同主编为熊璋教授。编委会及青年 AE 团队由国内外知名学者及优秀青年学者组成。本刊被 SCI、Ei、DBLP、INSPEC、SCOPUS 和中国科学引文数据库(CSCD)核心库等收录,为 CCF 推荐期刊;两次入选“中国科技期刊国际影响力提升计划”;入选“第4届中国国际化精品科技期刊”;入选“中国科技期刊卓越行动计划项目”。
《前沿》系列英文学术期刊
由教育部主管、高等教育出版社主办的《前沿》(Frontiers)系列英文学术期刊,于2006年正式创刊,以网络版和印刷版向全球发行。系列期刊包括基础科学、生命科学、工程技术和人文社会科学四个主题,是我国覆盖学科最广泛的英文学术期刊群,其中13种被SCI收录,其他也被A&HCI、Ei、MEDLINE或相应学科国际权威检索系统收录,具有一定的国际学术影响力。系列期刊采用在线优先出版方式,保证文章以最快速度发表。
中国学术前沿期刊网
http://journal.hep.com.cn

特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






