|
|
|
|
|
上海交通大学俞凯教授团队文章——基于声学词嵌入的端到端语音合成方法 | MDPI Applied Sciences |
|
|
论文标题:Acoustic Word Embeddings for End-to-End Speech Synthesis(基于声学词嵌入的端到端语音合成方法)
期刊:Applied Sciences
作者:Feiyu Shen, Chenpeng Du and Kai Yu
发表时间:27 September 2021
DOI:10.3390/app11199010
微信链接:
https://mp.weixin.qq.com/s?__biz=MzI1MzEzNjgxMQ==&mid=2650042375&idx=2&sn=
151c5c62ae0d5583c474b10c284d5428&chksm=f1d9cac3c6ae43d556bf64fb78ad7179
03d668684fdcafaee7dd0ffd1d686fc17a573d1c6c20&token=497878244&lang=zh_CN#rd
期刊链接:
https://www.mdpi.com/journal/applsci
通讯作者介绍

俞凯 教授
上海交通大学
主要研究方向为交互式人工智能、语音及自然语言处理和机器学习的研究和产业化工作。
语音合成是实现人机交互的关键问题之一,来自上海交通大学跨媒体语音智能实验室的俞凯团队近期在Applied Sciences上发表了一篇论文,研究了基于声学词嵌入的端到端语音合成方法。
引言
近年来,基于序列到序列生成架构的端到端文本语音合成 (TTS) 模型,在生成自然语音方面取得了巨大成功。为了避免逐帧递减情况的出现,提出了非自然生成的TTS模型,如FastSpeech和FastSpeech2,以提高语音生成速度。然而,词汇识别对于TTS系统生成高度自然的语音非常重要,但大多数端到端TTS系统只使用音素作为输入标记,而忽略了音素来自哪个词汇的信息。
之前的研究使用预先设置的语言词汇嵌入音素序列作为TTS系统的输入,但由于语言信息与单词如何发音没有直接关系,这些词汇的嵌入几乎没有对TTS质量的提高产生影响。本文提出了一种与TTS系统联合训练的词声学嵌入方法。在LJSpeech数据集上的实验表明,词声学嵌入显著提高了音速级韵律预测在训练集和验证集上的似然度。对合成音频自然度的主观评价表明,加入声学词嵌入的系统明显优于纯TTS系统和其他使用预设置的词嵌入的TTS系统。
设计亮点
1. 提出基于词声学嵌入 (Acoustic Word Embedding,AWE) 联合训练的端到端TTS系统,以帮助提高韵律和自然度;
2. 利用基于GMM的韵律建模方法对合成音频的韵律进行客观度量;
3. 探索词编码器最佳结构与词频筛选的最佳阈值;
4. 测试后的主观评价表明,AWE比预训练的词嵌入具有更好的自然性。
基于声学词嵌入的端到端语音合成方法
Part1:端到端语音合成
本文将FastSpeech2选为声学模型,但并没有明确考虑韵律建模,使得在没有主观听力测试的情况下,很难客观评价TTS系统的韵律预测性能。基于此,本研究在模型中引入一个音素级的韵律预测模块,该模块可以自回归地预测每个音素的韵律嵌入分布。与标准的Fastspeech2系统相比,它不仅可以提高自然度,而且允许使用韵律嵌入的对数似然度来轻松客观地评估音素级韵律预测性能,如图1所示。
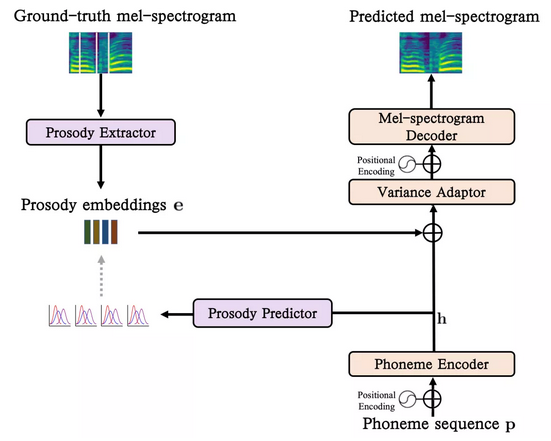
图1. 基于GMM韵律建模的端到端语音合成。
Part2:声学词嵌入
现在流行的TTS系统大多使用音素作为声音输入标记,而忽略了音素来自哪个词汇的信息。然而,词汇识别对于TTS系统生成高度自然的语音非常重要。本文提出利用声学词嵌入来进行自然语音合成,在传统的TTS系统中引入词编码器和词音素对齐器,其架构如图2所示。
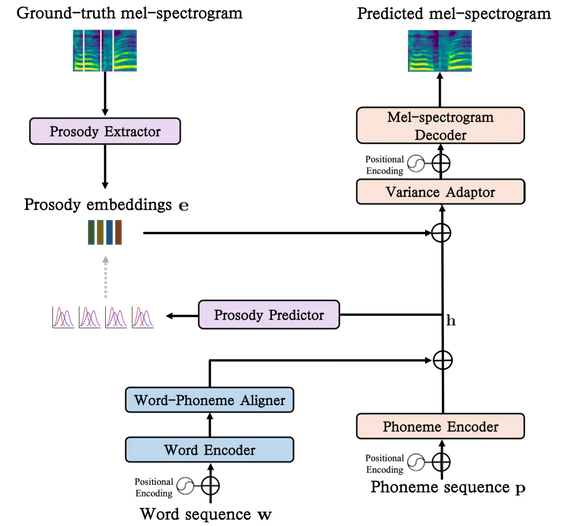
图2. 带有声学词嵌入的模型体系结构。
实验设置及结果
1. 实验设置
本文TTS模型基于Fastspeech2 (GMM的韵律建模)。将GMM中的高斯分量个数设为20,Adam优化器与Noam学习率调度策略一起用于TTS训练。研究者使用320mel-spectrogram作为声学特征,帧移12.5ms,帧长50ms。采用MelGAN作为声码器进行波形重构。
2. 词编码器架构
比较了三种常见词编码器结构的性能。
(1) None:不使用词编码器的基线;
(2) BLSTM:一层512维双向LSTM;
(3) Transformer:6层512维Transformer模块;
(4) Conv+Transformer:一层核大小为3的1D-CNN,然后是六层512维Transformer模块。
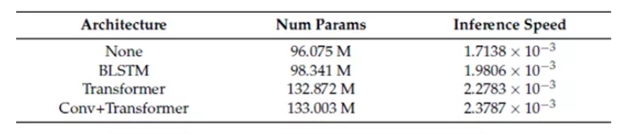
表1. 各种编码器架构的参数数量和推理速度 (秒/帧)。
3. 词频阈值

表2. 不同词频阈值下的词汇量和OOV。
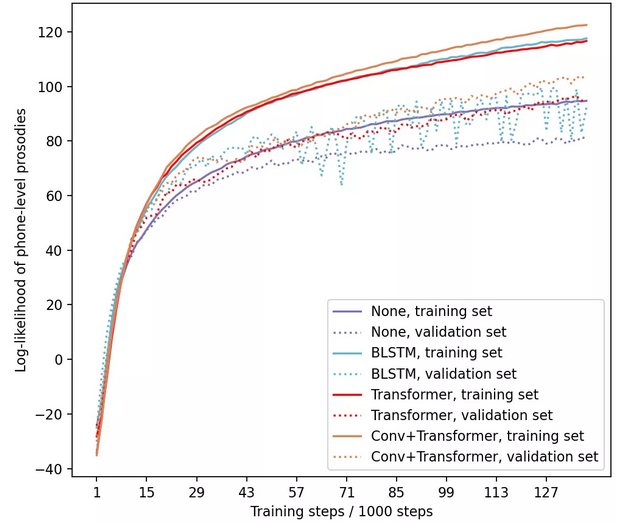
图3. 不同词频阈值的音素语音韵律的对数似然曲线。
结论
本文提出了一种在TTS系统中直接训练词声学嵌入的创新方法。音素序列和词序列分别通过两个编码器,共同作为TTS系统的输入,然后将两个输出隐藏状态拼接起来进行音素级韵律预测。本文在LJSpeech数据集上的实验表明,使用卷积与Transformer的叠加结构作为词编码器的效果最好。此外,词频阈值的选择应谨慎,阈值过大或过小都会导致性能下降。最后,本文将提出的系统与不使用词汇信息的基线和使用预训练的词嵌入的几个工作进行了比较。主观听力测试显示,在自然度方面,本文提出的系统优于其他所有系统。
Applied Sciences期刊介绍
主编:Takayoshi Kobayashi, The University of Electro-Communications, Japan
期刊主题涵盖了应用物理学、应用化学、工程、环境和地球科学以及应用生物学的各个方面。


特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






