|
|
|
|
|
鹏城实验室等发布具身智能新成果VidMan |
|
刷新具身智能CALVIN榜单最佳成绩 |
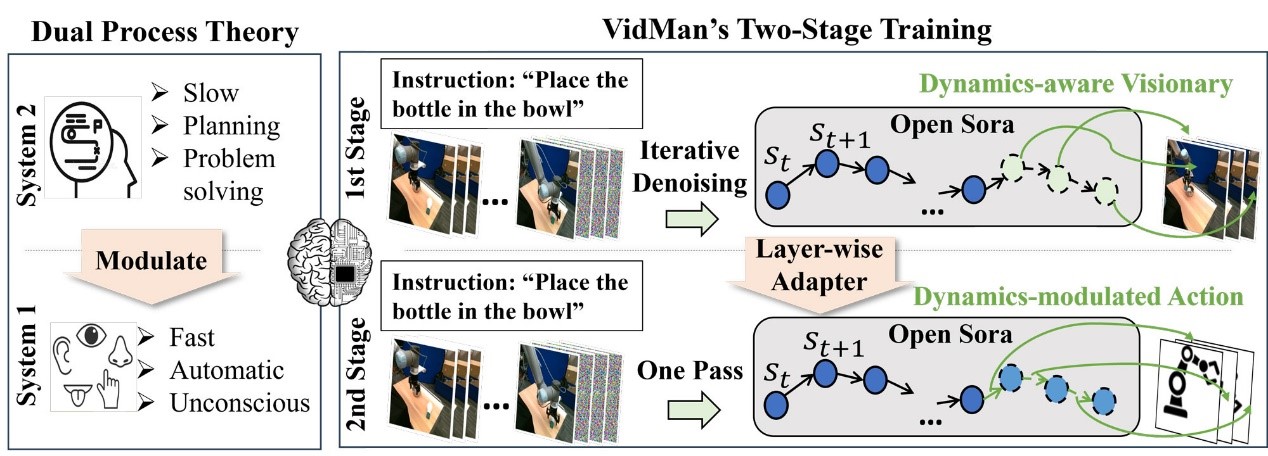 人类双程认知过程和VidMan的对应关系。研究团队供图
人类双程认知过程和VidMan的对应关系。研究团队供图
近日,鹏城实验室与中山大学等联合开展对具身智能多模态感知-规划-控制一体的研究并攻克了具身智能数据利用效率低下的难题,同步在基于“中国算力网”的大规模高速运算集群“鹏城云脑”上实现了最新的具身智能领域学术成果——VidMan(Video Diffusion Model for Robot Manipulation)具身智能操控模型。
记者获悉,该模型通过结合人类双程认知过程以及视频扩散生成模型Open-Sora,能够提升动作估计的精度和抓取成功率,强化预测未来图像的能力。目前,该模型已在具身智能主流榜单CALVIN零次学习长程任务中夺得最佳表现。
当前,缺乏大规模、高质量、多模态的开源数据集,是制约具身智能领域发展的重要因素。而最近的研究工作Open-Sora表明,利用大规模在线视频数据训练的视频扩散生成模型,在理解和预测长序列现实世界复杂物理动态方面具有巨大潜力。
为此,鹏城实验室联合中山大学、华为诺亚方舟实验室等创造性地提出了一种基于视频扩散生成模型的机械臂操控模型VidMan,切实解决了训练具身大模型的数据来源的瓶颈问题。
据介绍,该模型能够挖掘视频扩散生成模型学习的隐式物理世界规律,将动作估计建模成为视频帧之间的逆动力学过程,并基于双程认知理论提出双阶段训练策略,将视频扩散生成模型转换于指导下游机器人控制,显著提高机器人动作预测准确性和任务完成表现。
VidMan已在CALVIN榜单任务中超过了谷歌RT-1-X、字节跳动GR-1以及卡内基梅隆大学3D Diffuser Actor等世界先进模型。同时,该模型和有关方法已被国际顶级学术会议NeurIPS 2024接收并发表,并在在OpenI启智社区开源。
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。






