近日,中国科学院北京纳米能源与系统研究所王中林院士、王杰研究员、周灵琳副研究员在《先进材料》发表论文,提出一种自供电摩擦电立体声学传感器(SAS)。研究人员通过缩减摩擦材料振动膜厚度、振动膜半径等条件,获得了较宽的频率识别范围和高信噪比,在1.77立方厘米的小尺寸上实现了超高灵敏度识别。该传感器能克服嘈杂界面干扰,可用于人机交互的全方位声音识别和追踪。
 传感器应用场景。受访者供图
传感器应用场景。受访者供图
?
高效实时的人机交互对智能机器人发展意义重大。基于声学传感器的人机交互在智能机器人高效通信中扮演着重要角色,但传统声学传感器受外部电源供应、低灵敏度、窄频率带宽和制造工艺复杂等因素限制,难以同时实现在嘈杂环境中的声音识别和准确跟踪,也难通过声音接口实现直接高效的人机交互。
前期研究中,研究人员提出基于压电效应的自供电声学传感器,实现了在嘈杂环境中对多方向声源的识别。但这种声学传感器输出信号较弱且制造工艺复杂。因此,开发具有高灵敏度、高信噪比,以及在嘈杂环境中全方位声音识别和追踪能力的声学传感器,是实现高质量人机交互的迫切任务。
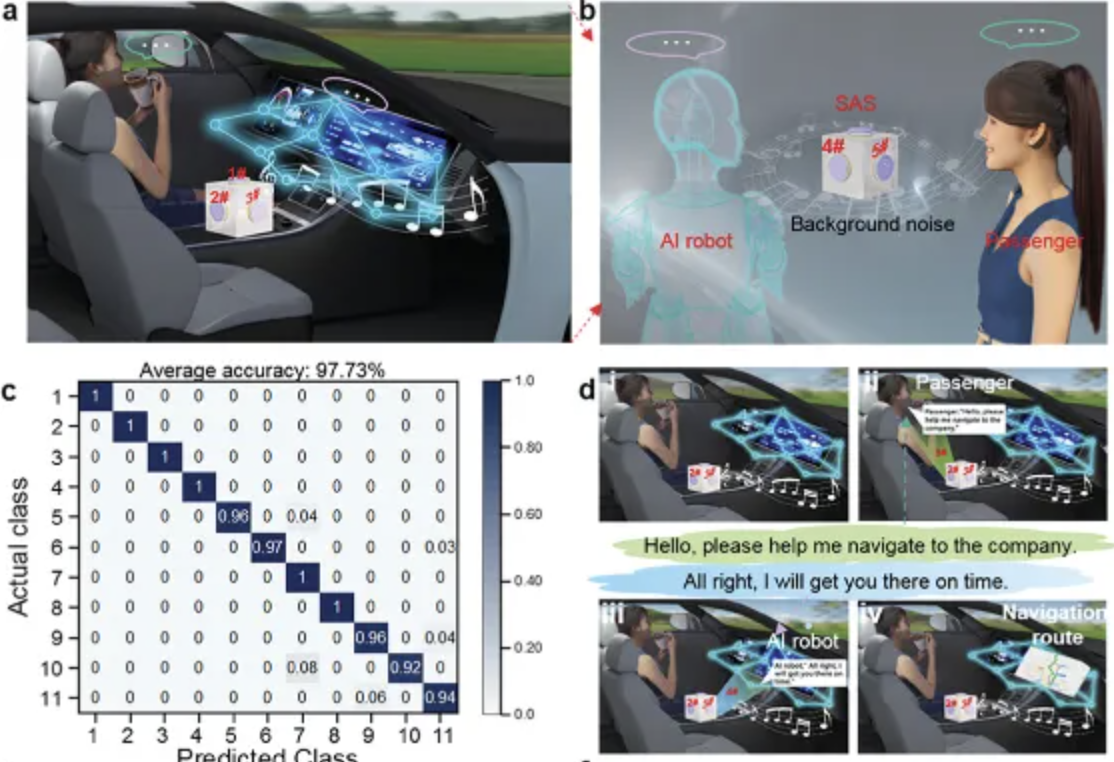
在此基础上,研究团队提出自供电摩擦电立体声学传感思路,它采用3D结构,除底面外5个平面都配备相同的层叠式自供电摩擦电声音传感器(TAS)设备。
“这使声音信号能够主动转换为电信号。”王杰说,“这种独特的配置形成了一个全方位波束形成阵列,促进了声源的识别和追踪。”
王杰介绍说,SAS结合了摩擦起电和静电感应原理,能主动将声音信号转换为电信号,无需额外的信号处理,实现高灵敏度和宽频率响应。因为具备高灵敏度、宽频率响应范围、自供电、低成本、小尺寸和简单结构的特点,已在应用中充分展现优势。
实验表明,利用SAS的全方位声音识别和追踪能力,以及其对不同声源和方向的差异化谐振频率响应,显著提高了从嘈杂环境中高效提取目标信号的能力,使平均深度学习准确率达到98%。此外,SAS能够在辅助会议系统中能同时识别多个体的声音,也能在自动驾驶车辆背景音乐下识别驾驶指令,这标志着基于语音的人机交互系统取得了新的进展。
相关论文信息:https://doi.org/10.1002/adma.202413086
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。






