?
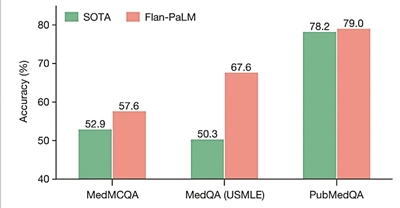
图为研究团队的方法和现有技术的比较。Flan-PaLM 540B模型在MedQA,MedMCQA和PubMedQA数据集上均超过了以往最先进的SOTA,每列上方显示的是准确率百分比。图片来源:《自然》
你在网上搜过“我哪哪疼是不是得了啥啥病”吗?答案可能不尽如人意。但随着ChatGPT等大型自然语言模型(LLM)风生水起,人们开始尝试用它来回答医学问题或医学知识。
不过,靠谱吗?
就其本身而言,人工智能(AI)给出的答案是准确的。但英国巴斯大学教授詹姆斯·达文波特指出了医学问题和实际行医之间的区别,他认为“行医并不只是回答医学问题,如果纯粹是回答医学问题,我们就不需要教学医院,医生也不需要在学术课程之后接受多年的培训了。”
鉴于种种疑惑,在《自然》杂志新近发表的一篇论文中,全球顶尖的人工智能专家们展示了一个基准,用于评估大型自然语言模型能多好地解决人们的医学问题。
现有的模型尚不完善
最新的这项评估,来自谷歌研究院和深度思维公司。专家们认为,人工智能模型在医学领域有许多潜力,包括知识检索和支持临床决策。但现有的模型尚不完善,例如可能会编造令人信服的医疗错误信息,或纳入偏见加剧健康不平等。因此才需要对其临床知识进行评估。
相关的评估此前并非没有。然而,过去通常依赖有限基准的自动化评估,例如个别医疗测试得分。这转化到真实世界中,可靠性和价值都有欠缺。
而且,当人们转向互联网获取医疗信息时,他们会遭遇“信息超载”,然后从10种可能的诊断中选择出最坏的一种,从而承受很多不必要的压力。
研究团队希望语言模型能提供简短的专家意见,不带偏见、表明其引用来源,并合理表达出不确定性。
5400亿参数的LLM表现如何
为评估LLM编码临床知识的能力,谷歌研究院的专家谢库菲·阿齐兹及其同事探讨了它们回答医学问题的能力。团队提出了一个基准,称为“MultiMedQA”:它结合了6个涵盖专业医疗、研究和消费者查询的现有问题回答数据集以及“HealthSearchQA”——这是一个新的数据集,包含3173个在线搜索的医学问题。
团队随后评估了PaLM(一个5400亿参数的LLM)及其变体Flan-PaLM。他们发现,在一些数据集中Flan-PaLM达到了最先进水平。在整合美国医师执照考试类问题的MedQA数据集中,Flan-PaLM超过此前最先进的LLM达17%。
不过,虽然Flan-PaLM的多选题成绩优良,进一步评估显示,它在回答消费者的医疗问题方面存在差距。
专精医学的LLM令人鼓舞
为解决这一问题,人工智能专家们使用一种称为设计指令微调的方式,进一步调试Flan-PaLM适应医学领域。同时,研究人员介绍了一个专精医学领域的LLM——Med-PaLM。
设计指令微调是让通用LLM适用新的专业领域的一种有效方法。产生的模型Med-PaLM在试行评估中表现令人鼓舞。例如,Flan-PaLM被一组医师评分与科学共识一致程度仅61.9%的长回答,Med-PaLM的回答评分为92.6%,相当于医师作出的回答(92.9%)。同样,Flan-PaLM有29.7%的回答被评为可能导致有害结果,Med-PaLM仅5.8%,相当于医师所作的回答(6.5%)。
研究团队提到,结果虽然很有前景,但有必要作进一步评估,特别是在涉及安全性、公平性和偏见方面。
换句话说,在LLM的临床应用可行之前,还有许多限制要克服。
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。