|
|
|
|
|
文心衍生模型PaddleOCR创GitHub“星”数记录 |
|
|
近日,百度文心衍生模型PaddleOCR在GitHub上的Star数突破73.3K,超越谷歌旗下开源OCR标杆产品Tesseract OCR(73.2K),成为全球Star数最高的OCR项目。
据了解,Tesseract OCR诞生于1985年,最初由惠普实验室研发,2005年开源后由Google接手维护并持续迭代,是OCR领域延续近四十年的技术标杆,长期位居GitHub OCR项目Star数榜首。此次PaddleOCR实现超越,显示了大模型驱动下中国开源项目的活力。
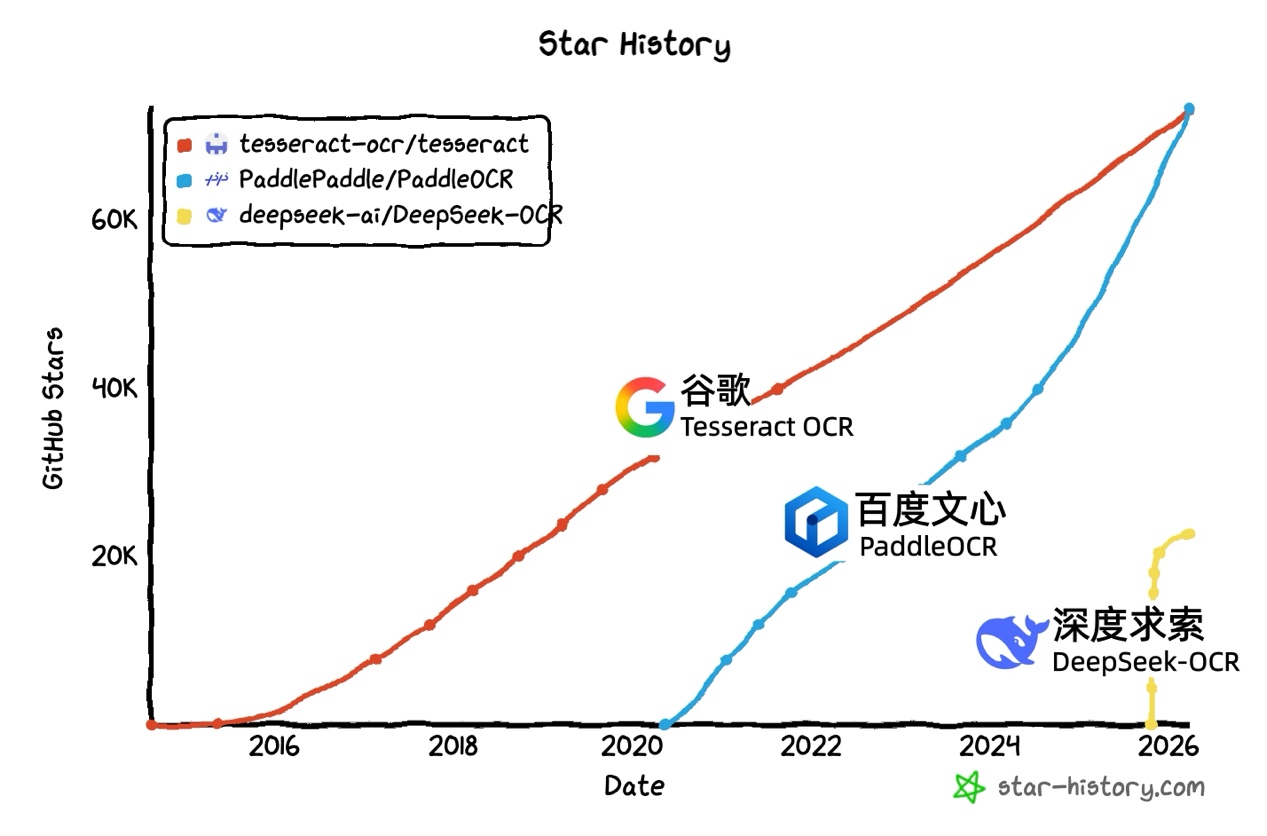
不同OCR模型Star数量变化图。百度供图
据相关技术负责人介绍,PaddleOCR基于文心大模型训练而来,是文心大模型多模态能力的重要部分,支持超100种语言识别,用户覆盖160个国家和地区。1月29日,新一代文档解析模型PaddleOCR-VL-1.5在 OmniDocBench V1.5 榜单中取得了全球SOTA成绩。
近年来,大模型成为OCR赛道增长的重要动力。Star History数据显示,PaddleOCR在GitHub上的Star自2024年起呈现爆发式增长。2025年以来,OCR更成为大模型厂商布局的重点方向,DeepseekOCR、HunyuanOCR、GLM OCR等产品相继发布。
近期,PaddleOCR同步升级了服务能力。官网免费每日解析页数由1万提升至2万,用户还可通过OpenClaw直接调用PaddleOCR Skill,免费获取高精度PDF解析能力。与此同时,PaddleOCR OCEAN生态联盟宣布成立,并面向核心开源贡献者、深度企业用户及全球平台伙伴开放,首批成员包括Hugging Face、Dify、RAGFlow、Cherry Studio、Milvus等全球平台伙伴,将共同推动OCR技术在更广泛场景中的应用落地。
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。