|
|
|
|
|
首个AI驱动植物基因组数据库DeepPGDB成功构建 |
|
|
华南农业大学农学院教授王少奎团队携手广东省农业科学院水稻研究所副研究员胡海飞,成功构建首个AI驱动的植物基因组数据库DeepPGDB。该系统通过融合多个语言模型、采用QLoRA微调技术、运用检索增强生成与提示工程方法,开创了“自然语言交互式基因组分析”的全新范式。相关成果近日发表于《植物通讯》(Plant Communications)。
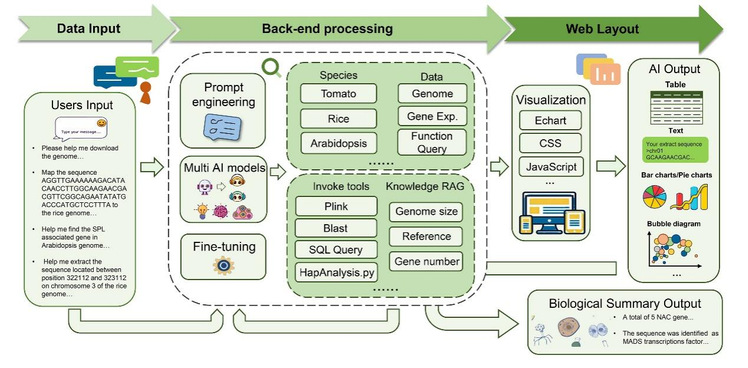 DeepPGDB架构示意图。研究团队供图
DeepPGDB架构示意图。研究团队供图
?
过去10年,组学技术迅猛发展。在植物科学领域,超1000个物种完成染色体级别的高质量基因组解析,水稻、拟南芥等模式植物更是率先进入群体基因组时代。然而,海量数据背后,众多有生物学背景的研究者却陷入分析困境。传统研究方法要求研究者精通生物信息学工具、熟练命令行操作及复杂数据处理流程,这成为跨领域研究的重大阻碍。随着生成式大语言模型取得突破,科研范式发生根本性变革,DeepSeek等大模型为研究者提供智能数据处理助手,AI智能体的出现也让基因组数据库智能化成为可能。
DeepPGDB的核心创新在于其智能调度架构。该系统能精准理解用户以自然语言提出请求的真实意图,自动判别任务类型并调用相应工具。无论是基因组序列检索、BLAST比对、基因定位查询,还是基因家族分析,用户只需在对话框输入问题,AI引擎就会自动生成标准化操作指令,在后端完成数据提取与处理,最终以对话形式返回结构化结果。系统还特别设计了多注释版本适配机制,可智能识别基因ID、基因名称等不同编号体系,有效解决了基因名称标识难题。
除基础查询功能外,DeepPGDB还配备强大的可视化引擎。该引擎集成ECharts动态图表系统,支持基因表达谱可视化、富集分析交互展示等高级功能。在群体遗传学分析方面,系统整合PLINK工具,可直接处理群体基因组变异数据。研究团队推出的summarize模块,能基于检索结果进行多步生物学推理,如解析水稻亚种单倍型分化规律、计算基因蛋白理化性质等,真正实现从“数据查询”到“知识发现”的跨越。
在模型选择上,经严格测试,团队最终选定14B参数推理模型作为系统核心模型,在保证意图识别准确率的同时,实现了最优响应速度,且部署门槛较低。通过独特的微调方案,系统在长提示词和短提示词两种模式下均能保持卓越性能。
DeepPGDB的上线,为研究者提供了高效分析工具,将成为推动农业创新、物种保护和生物技术发展的重要引擎。未来,团队将持续拓展物种数据资源,深化多组学整合能力,完善智能推理框架。
相关论文信息:https://doi.org/10.1016/j.xplc.2025.101494
DeepPGDB访问信息:https://www.deeppgdb.chat
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。






