7月11日,由临港实验室牵头,联合上海科学智能研究院、上海交通大学、东京大学国际神经智能研究中心等多家单位,共同发布了全球首个跨物种大脑空间转录组基础模型BrainBeacon。
生命科学中的细胞“语言”由DNA、RNA、蛋白质和基因表达等分子“词语”构成。开发基于这种特殊“语言”的人工智能(AI)细胞大模型,不仅可以帮助我们深入解析疾病机制,还能加速药物靶标发现。
当前,单细胞转录组大模型已经能够整合数千万细胞数据,实现了跨器官、跨物种的通用细胞表征。空间单细胞转录组技术则进一步突破了单细胞转录组的局限,能够更全面地揭示细胞间互作和微环境调控机制,但目前尚未出现全面的空间转录组基础模型。
研究团队此次开发的BrainBeacon,模型训练基于横跨4个物种(人、食蟹猴、狨猴、小鼠)和5种主流空间组学平台的数据,覆盖总面积超过210000平方毫米的全脑空间转录组数据,细胞总数超过1.33亿。
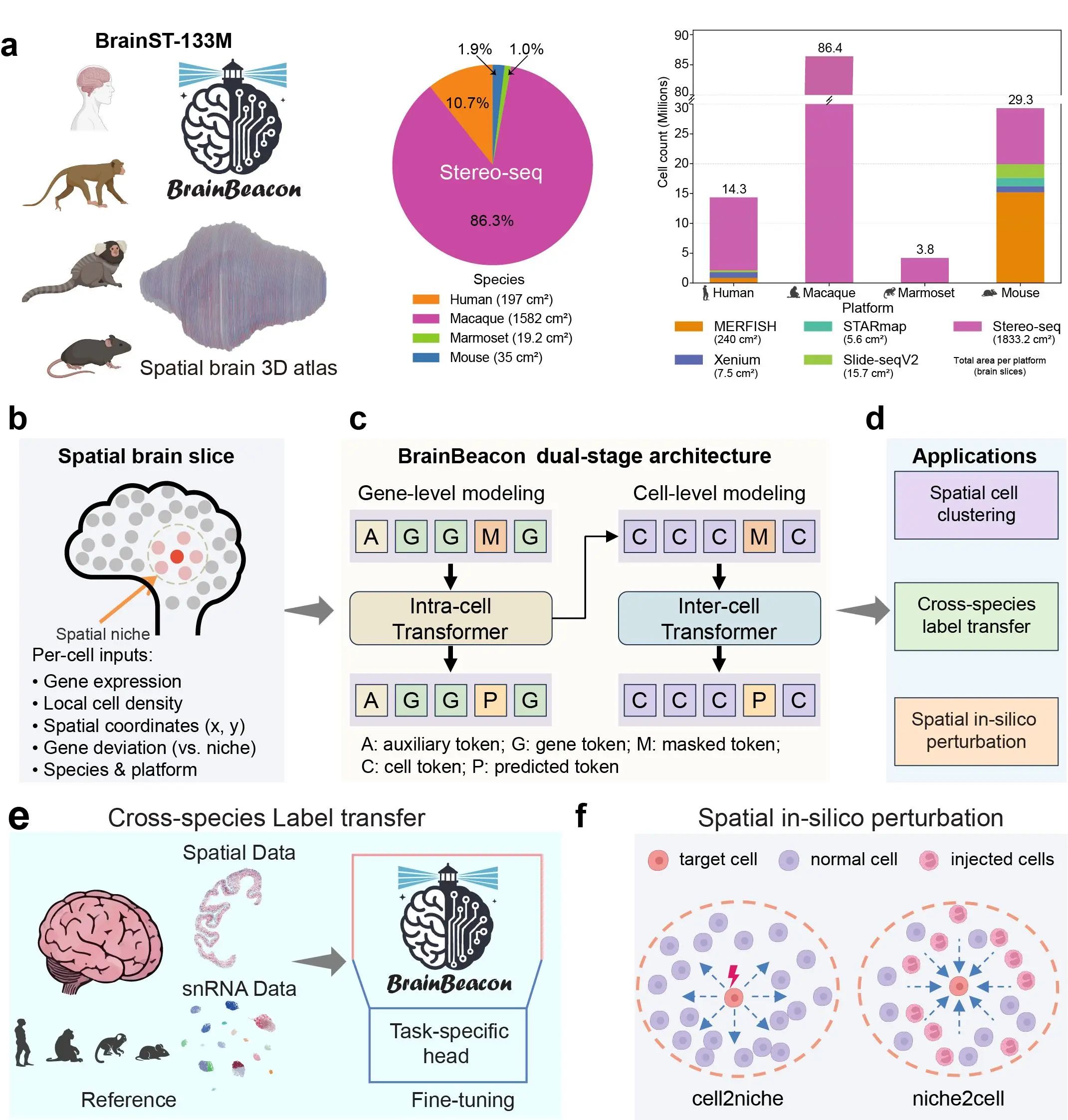 BrainBeacon模型架构与训练数据概览。图片由研究团队提供
BrainBeacon模型架构与训练数据概览。图片由研究团队提供
?
模型采用双阶段Transformer架构,分别模拟细胞内部基因依赖与细胞之间空间依赖,实现统一的跨物种表征学习,且在多个平台和物种的公开数据集上实现了高精度的零样本空间细胞分类能力,表现优于现有主流模型。
此外,BrainBeacon可通过“参考引导微调”机制,在某一物种高质量空间图谱上进行微调后,迁移预测其他物种的大脑组织切片,准确识别同源亚型与脑区结构,探究多物种之间的保守性。其内置的“空间数字扰动”功能,则突破了传统组学扰动仅限于细胞内部的局限,可模拟细胞和邻域微环境之间的双向扰动。
研究团队表示,BrainBeacon的发布标志着空间转录组进入“结构重建+状态干预”双轮驱动时代,也将成为连接“智能感知—空间理解—干预预测”的关键桥梁。其高通量训练能力、泛化表示结构与虚拟实验平台,可为跨模态图谱构建、疾病机制建模、AI靶标筛选与药物发现、多物种智能脑图谱基座模型建设等多个研究方向提供基础。
相关论文信息:https://doi.org/10.1101/2025.07.08.663729
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。






