|
|
|
|
|
无问芯穹打通七家国产芯片DeepSeek-R1适配 |
|
|
2月11日,专注于为人工智能提供算力等基础设施的“清华系”创企“无问芯穹”宣布,其已获得七家国产芯片鼎力支持,正打通DeepSeek-R1、V3在壁仞、海光、摩尔线程、沐曦、昇腾、燧原、天数智芯等七个硬件平台的多芯片适配优化,现开发者已可以通过Infini-AI异构云平台一键获取DeepSeek系列模型与多元异构国产算力服务。
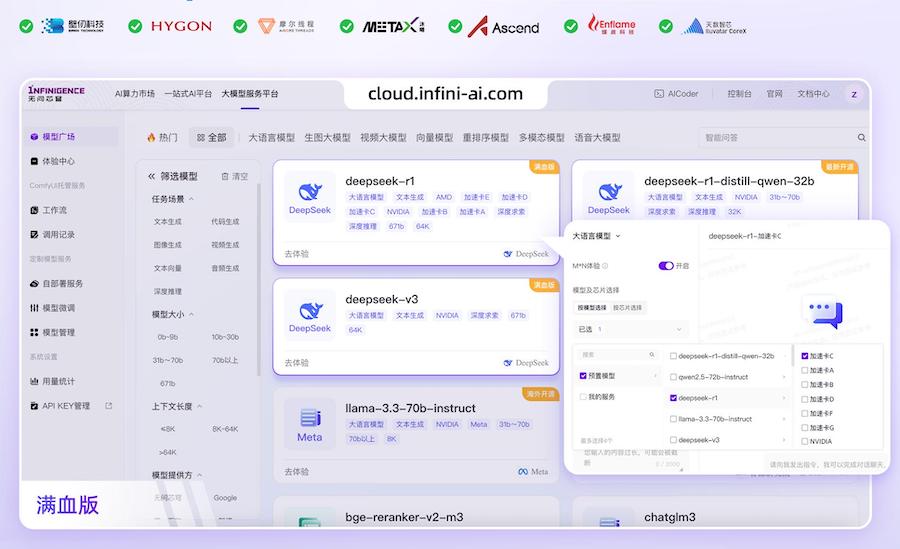 打通DeepSeek-R1、V3多芯片适配优化。 无问芯穹 供图
打通DeepSeek-R1、V3多芯片适配优化。 无问芯穹 供图
?
自蛇年春节前夕爆火,DeepSeek已牵动了国内超30家云服务商与近20家芯片企业宣布接入,俨然一场由DeepSeek引发的流量蛋糕切分大战。无问芯穹此次宣布打通7家国产芯片适配DeepSeek-R1,正将DeepSeek作为撬动可控国产算力的转机。
大部分国产大模型是通过国际主流芯片(如英伟达)训练得到,尚未与国内的AI系统、芯片形成闭环生态。无问芯穹联合创始人、CEO夏立雪表示, DeepSeek的突破激发了越来越多的下游应用创造力,未来行业日均tokens消耗量将达到百万亿级别,不仅将激发国产芯片的市场需求,也为打造全国产AI产业闭环,实现更可控的自主算力发展创造了有力条件。
在美国,模型、系统、芯片已经形成闭环生态。以英伟达为例,其GPU的主流地位与CUDA生态有直接关系,CUDA的护城河是软件堆栈,可以让研究人员和软件开发者更好地在GPU上编程和构建各种各样的应用,牵引下一代芯片的迭代方向。但是随着Transformer统一模型结构,大模型应用落地场景所需的算子数量大幅度收缩,CUDA的护城河正在变浅。
“某种程度上来说,CUDA已经是历史了。”夏立雪表示,DeepSeek作为开源模型,其之于AI 2.0时代,正如安卓系统之于移动互联网革命,将重构整个产业生态,引发链式反应,加快上层应用发展和下层系统“统一”增速,由此广泛调动起跨越软硬件和上下游的生态,一起加大投入“模型—芯片—系统”协同优化和垂直打通,从而继续“打薄”CUDA生态。
夏立雪举例说,这类协同优化工作包括根据新一代模型架构来定义未来芯片的底层电路实现,以及根据国产AI系统的互联通信方式来设计高效的混合专家模型结构等。
对此,无问芯穹提出了“三步走”模式来促进全国产AI产业闭环的打通——基于主流芯片开展极致软硬件协同优化,以有限算力实现国产模型能力追赶;推动国产芯片开放底层生态,搭建“异构”AI系统解决算力缺口,实现模型能力赶超;构建国产“同构”系统,支持Scaling Law持续发展,打造“国产模型—国产芯片—国产系统”的全国产AI产业闭环,实现更可控的自主算力发展。
获取多芯片适配版DeepSeek-R1:https://cloud.infini-ai.com/genstudio?source=U7Z9
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。






